mysql复制技术
mysql复制技术架构讲解:
一、mysql AB 复制技术(主从)(异步复制)
MySQL支持单向、异步(async)复制,复制过程中一个服务器充当主服务器,而一个或多个其它服务器充当从服务器。
mysql主 - - > mysql从
master slave
把主上的二进制日志(bin-log)的内容传到从上的一个新的日志叫relay-bin-log
从上的 IO 线程 负责传输
从上的 SQL 线程 负责从服务器解析日志
复制的过程:
1,slave端的IO线程连上master端,请求
2,master端返回给slave端,bin log文件名和位置信息
3,IO线程把master端的bin log内容依次写到slave端relay bin log里,并把master端的bin-log文件名和位置记录到master.info里。
4,salve端的sql线程,检测到relay bin log中内容更新,就会解析relay log里更新的内容,并执行这些操作;也就是说salve执行和master一样的操作而达到数据同步的目的
架构图:
1 | 客户 |
思考回答题:
1,主打开二进制日志,从要不要开二进制日志?
2,主和从的读写情况怎么分开?
二、一主多从复制构架
架构图
1 |
|
适合于以读为主的业务,使用多个salve分担读的压力,但要注意的是这种架构,salve越多,那么master复制的压力就越大
三、双主复制架构
1 | master A <--> master B |
双主架构最大的优点是,两台服务器实现数据互通,两台即能写又读,在任何一台服务器上写数据,另一台都会同步
思考题:
1、双主mysql复制构架,能同时写相同的数据吗?
2,两边可以写不同的数据吗?
可以通过业务程序层,指定一些表的写操作全在一端,另一些表的写操作全在另一端,也就是说两边不会同时写相同的表(当然这是理想状态,因为业务复杂的话会有表的联结等情况)
然后通过指定mysql复制的参数,一部分表或库会从A复制到B,另外一部分表或库从B复制到A就可以避免上面的问题了
或者两个库,一个库master A来写,另一个库master B来写
前面三个问题也说明了双主架构的第一种应用(就是两边写不关联的数据,互相复制),双主架构的第二种应用就是解决一主一从架构里主挂掉了的问题。
看下面的分析
mysql主 mysql从
思考:
问题1:如果一主一从,主挂了,slave能不能写,如果能写,主修好启起来后,salve写的数据如何传回给主?
答案:主挂了,slave应该要写,否则论坛不能发贴,只能看贴;
主修好后(假设一小时),slave写了这一小时的数据应该要想办法传回主才行。
方法一:DBA人为的把salve这一小时写的数据找出来再导入到主(如果很多表,一小时的操作也非常多,可以说几乎不可能找出这小时改变了啥)
方法二:使用类似rsync的同步方法,这是通过存储层来实现数据同步回去。备:是把整个数据目录复制过去。
方法三:DBA人为的把从这一小时改变的二进制日志(要确认slave打开二进制日志)给找出来然后应用到主上去
方法四:直接把一主一从架构改为双主,或者把一主一从反过改成一从一主
问题2: 上面的方法无论哪一种都会有一个问题,就是把从写的一小时数据传回给主需要一定的时间
就是假设这一小时slave创建了一个aaa表,主mysql修好启动后,
如果主马上接管从的写功能,这时前端程序马上给了一个insert into aaa的插入操作,这样肯定会出问题,因为创建aaa表的操作还没有从slave那传回来,如何解决?
解决方法一:人为控制主现在不能写,等slave的数据传回来后再写;但这样的话,等待时间太长了
解决方法二:就是把一主一从的架构改成双主的架构(假设master A和master B)
master A —> master B (平时主B只读,不写,只有到主A挂了,才会写)
挂一个小时
读写一个小时
修复后启动了
把读给A 写留给B
问题3: 改成双主后,master B在master A挂掉的一小时内帮他写了数据,A修好启起来后,B的数据可以自动传回A;但是如果数据量大的话,这个传回也可能需要一定时间,如果正好在这个传回时间内也出现了问题2的情况,又如何解决?
解决方法一:人为控制主不能写,这样的话等待时间很短(因为是自动传回来,跟手动导回来速度快很多),影响不大
解决方法二: 就直接把master B 做为新的写服务器,master A启动后,也只是做为读服务器;除非等下一次B挂了,A会重新成为写服务器(当然这是在两台服务器性能相等的情况下)
总结: 上面说明双主架构的两种应用
四、级联架构
1 | -- salve -- salve |
为了解决一主多从的master的复制压力
可以把slave做为下一级从机的master
加复制的级联层次,造成的延迟更长
所以这种架构并不是很推荐,一般会进行分拆集群
五、双主和级联合起来
1 | master --salve --slave |
优化原则:分
大型结构的数据量太大,要用到数据切分(水平,垂直)
mysql 复制技术部署
1、关闭iptables,selinux,NetworkManager
2、将主机名和IP写进hosts
3、使用yum rpm包或tar安装数据库,主从两台机安装一致
4、主:开启二进制日志,用于记录对表的增删改操作,并流传给从
5、主从设置server-id值,主的值比从要小
6、主:建立复制的帐号并授权
master A 主服务器ip:192.168.224.10
slave B 从服务器ip: 192.168.224.11
第一步,安装好8.0的Mysql
修改主、从配置文件 /etc/my.conf
主:master:在[mysqld]标签下加入下面二句
1 | [mysqld] |
备:slave:在[mysqld]标签下加入下面一句
1 | [mysqld] |
完成配置后重新启动mysql服务
主服务器上ll /usr/local//mysql/data/看下是否已经有二进制日志,mysql-bin.000001和mysql-bin.index
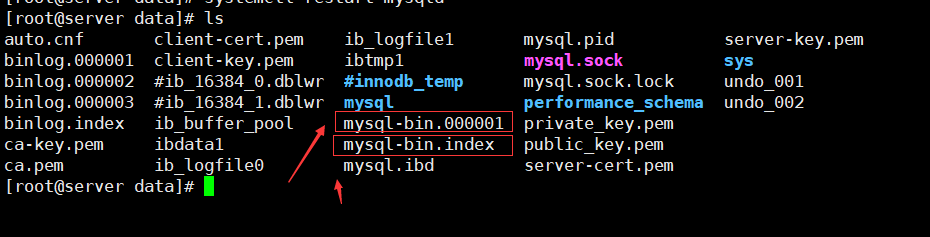
第二步:建立复制的帐号并授权
先创建用户密码为123.Shui!!@#
1 | create user 'aa'@'%' identified with mysql_native_password by '123.Shui!!@#'; |
然后授予复制权限
1 | grant super,replication slave on *.* to 'aa'@'%'; |
授权完成后,在从服务器上登陆测试 登陆成功后就退出
1 | mysql -uaa -h192.168.224.10 -p'123.Shui!!@#' |
第三步:给master加上锁,防止有新的数据写入
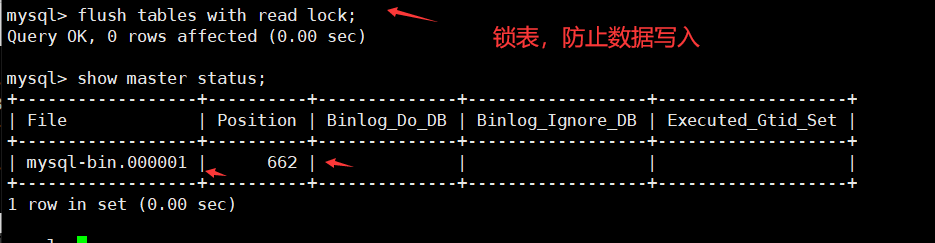
1 | flush tables with read lock; |
查看二进制日志记录的位置,配置从服务器要用,只要服务器开启二进制日志后才允许当主
1 | show master status; #查看主服务器配置 |
查看master
1 | show master status; |
备注:尝试在主服务器上使用命令show slave status; 查看是否有数据,因这台服务器是主服务器,所以条命令是看不到任何东西,是空的。
1 | mysql> exit |
查看主服务器的日志文件名是否和上面查出来的一致,配置从服务器要用
1 | ll /usr/local/mysql/data/ |
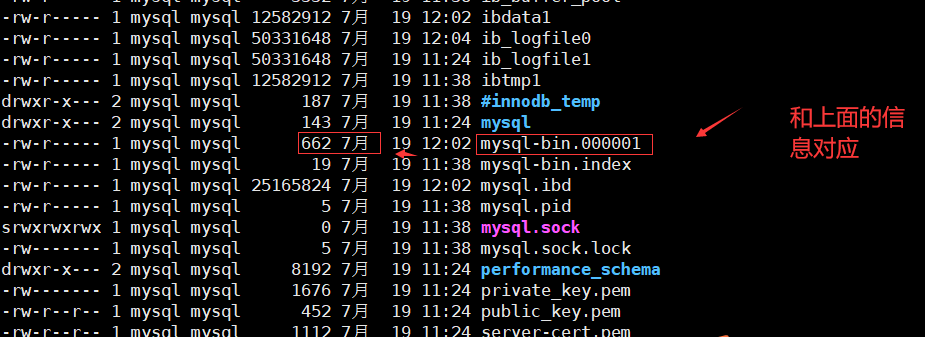
对照文件名是否一致
第四步:在从服务器slave端,配置mysql主从关系
切到从服务器192.168.224.11上面
先登陆数据库
1 | mysql -p |
停止从服务器复制线程:备注:默认该线程就是停止状态,执行该命令是告诉数据库该线程明确的要停止
1 | stop slave; |
配置主从关系:
该台服务器为从时,需要配置连接主服务器的信息,从服务器能不能在主服务器上面获取二进制日志,全靠下面的配置信息。
mysql> change master to #配置从服务器连接主服务器
-> master_user=’aa’, #主服务器建立复制的帐号
-> master_password=’123.Shui!!@#’, #密码
-> master_host=’192.168.224.10’, #主服务器IP
-> master_port=3306, #端口,注:不能加引号
-> master_log_file=’mysql-bin.000001’, #主上面查到的文件名
-> master_log_pos=662 #主上面查到的位置号
1 | change master to master_user='aa',master_password='123.Shui!!@#',master_host='192.168.224.10',master_log_file='mysql-bin.000001',master_log_pos=662; |
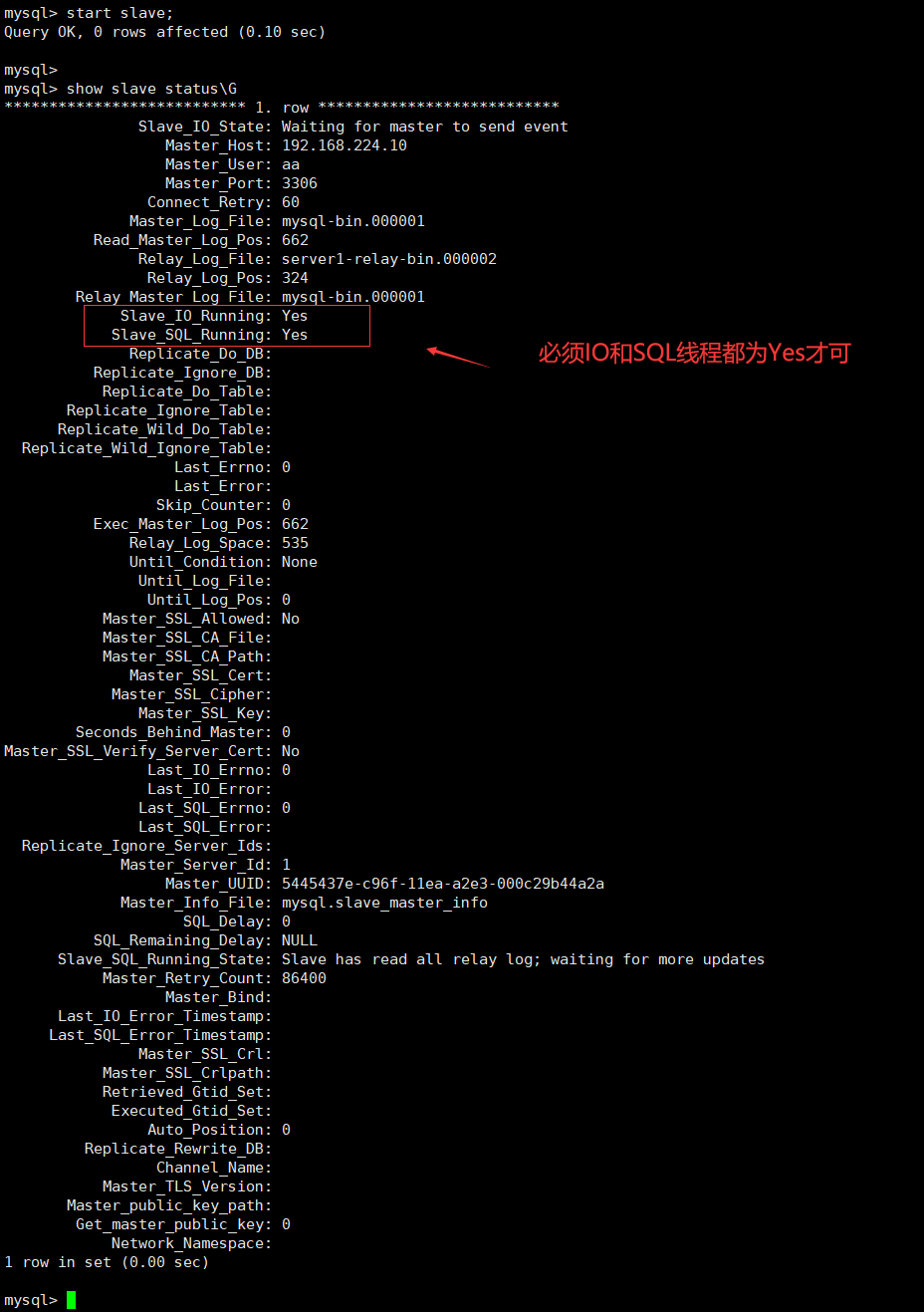
配置连接主服务器信息后,在从服务器上启动slave线程。
1 | start slave; |
启动完成后,再查看slave线程连接主服务器的状态
1 | show slave status\G |
1 | START SLAVE 启动除group_replication_recovery和 group_replication_applier通道之外的所有通道的复制线程 。 |
警告
请RESET SLAVE谨慎使用,因为此语句将删除所有现有通道,清除其中继日志文件,并仅重新创建默认通道。
第五步:在主服务器master端解锁mysql:
1 | unlock tables; |
第六步:测试
在主服务器上创建库、表和插入表数据后,在从服务器查看是否有相同数据
1 | create database aa; |
在从服务器上查看
1 | select * from aa.test; |
第七步:查看日志文件:
在从服务器上查看(192.168.224.11)
1 | cat /usr/local/mysql/data/server1-relay-bin.index |
题外:
尝试登陆从服务器: 192.168.224.11
1 | mysql -uroot -p'123.Shui!!' |
在从服务器上面登陆库、表并使用insert插入数据。
这时再登陆主服务器:192.168.224.10
1 | mysql -uroot -p'123.Shui!!' |
在主服务器上查看是否有从服务器创建和插入的数据。
备注:只有master写,slave可以看到,slave写,master看不到
如果复制出现问题
(要模拟问题的话,在从上创建一个库,然后在主上也创建这个库,就会冲突,造成复制出现问题),
重做复制集群只需要重新在从上执行stop slave; change master to …… ; start slave;
测试:把从重启后,再上去查看状态,还是连接的,没什么影响
把主重启后,再去slave上去查看状态,发现重试时间为60秒,等60秒后又自动连接OK了
如果想要改这个60秒的话,可以把从服务器上的master.info文件里的60直接改成30(rpm版测试有点问题)
1主多从的做法
1 | ->slave |
就是上面的步骤有几个从就做几次,
双主架构
1 | master - master |
把上面的1主1从,反过来做一遍,在上面的slave机也打开二进制日志,反着做一遍就行,注意做的过程中,保证数据一致
做好的架构,只要两边不同时操作相同的数据,就不会出现复制不一致的问题;
或者是在业务程序层,将一部分的写操作定义到master A,另一部分的写操作定义到master B
级联架构
master A 主服务器ip:192.168.224.10
slave B 从服务器ip:192.168.224.11
slave C 从服务器IP:192.168.224.12
master A -slave B -slave C
把中间的从也要打开二进制日志。但是它默认不把应用master的操作记录到自己的二进制日志。所以需要打开一个参数让它记录,才可以传给第三级的从
本文需要验证的疑问:
从库做为其他从库的主库时 log-slave-updates参数是必须要添加的,因为从库要作为其他从库的主库,必须添加该参数。该参数就是为了让从库从主库复制数据时可以写入到binlog日志,为什么要用这个参数写binlog日志呢,不是在配置文件中开启log-bin =mysql-bin选项就可以吗?
答:从库开启log-bin参数,如果直接往从库写数据,是可以记录log-bin日志的,但是从库通过I0线程读取主库二进制日志文件,然后通过SQL线程写入的数据,是不会记录binlog日志的。也就是说从库从主库上复制的数据,是不写入从库的binlog日志的。所以从库做为其他从库的主库时需要在配置文件中添加log-slave-updates 参数。
在/etc/my.cnf文件里加上以下二句:
1 | max_allowed_packet=20M #代表应用的日志大小 |
在服务器里查看参数
1 | show variables like '%max_allowed%'; |
架构图:
1 | master A slave B slave C |
日志应用流程:
1 | bin-log relay-bin-log relay-bin-log |
2主多从+级联
2主就是把前面的双主架构做一遍,多从就是在新服务器上把从服务做一遍,如果要加级联就是再把级联架构做一遍。
Mysql 基于表复制技术
复制库、表和表内容参数:可使用show slave status\G 命令看到以下参数
Replicate_Do_DB: #接受哪个库的复制:必须在指定的库下操作才能复制。包括表结构和表数据。
Replicate_Ignore_DB: #忽略哪个库的复制
Replicate_Do_Table: #接受哪个表的复制:注:只能指定某个库下的某个表的内容更新与修改,例:aaa.a3
Replicate_Ignore_Table: #忽略哪个表的复制
Replicate_Wild_Do_Table: #通配符表示复制哪些表:注:接收某个库下的所有表内容的修改,例:aaa.%
Replicate_Wild_Ignore_Table: #通配符表示忽略哪些表
实例说明:
master A slave B
1、先把两台做成ab复制的架构
此时在master上做任何创建库、表或插入数据等动作,从服务器都会复制过来。
2、现在的业务需求是:
要求:把master的aaa库下的表复制到slave上,其它的库都不要
3、为了满足需求我们在slave b的my.cnf配置文件的[mysqld]参数组里加上
1 | replicate_do_db=aaa #只接受aaa库的复制 |
4、重启slave b,然后测试
测试结果为
->在master上创建aaa库:create database aaa;
->在master创建aaa.a1表:create table aaa.a1(id int(1));
->并插入数据insert into aaa.a1 values(1);
->回到slave上查看有aaa库,也有a1表,但没有数据
如果要同步aaa.a1表下的数据,master要进到aaa库下操作才可以
->在master上操作,use aaa;然后再插入数据:insert into aaa.a1 values(2);
->回到slave上查看aaa库的a1表数据,这时就有了
如果想要复制该库下所有的表数据,这时就要加入另外一个参数
5、解决方法:
在slave b上的my.cnf文件的[mysqld]标签下加上以下参数,就可以复制aaa库下的所有表和表内容了
1 | replicate_wild_do_table=aaa.% #%是通配符 |
6、重启slave b 然后测试
测试步骤:
->在master创建aaa.a2表:create table aaa.a2(id int(1));
->并插入数据insert into aaa.a2 values(1);
->并给aaa.a1表也插入数据:insert into aaa.a1 values(2);
->回到slave上查看aaa库下是否有a2表,a2和a1表是否有上面插入的数据。
表复制技术完成
多源复制
注意:mysql多源复制技术仅支持5.7以上版本mysql
官方文档
1 | https://dev.mysql.com/doc/refman/8.0/en/channels-startup-options.html |
1、多源复制的特性
1.1 和主从复制技术一样,都是通过mysql的二进制日志(binlog)来实现数据的同步
2、什么地方需要用到多源复制
2.1 在此之前,我们讲到了mysql主从复制技术,但考虑一下,如果我有两台不同数据的mysql服务器,该如何才能实现同时使用一个slave进行数据同步备份呢?
提示:在做多源复制之前先把之前搭建好的双主关掉
1 | stop slave; |
参数讲解:
必须正确配置 以下启动设置才能使用多源复制。
-
必须将其设置为
TABLE。如果将此变量设置为FILE,则尝试向副本添加更多源失败ER_SLAVE_NEW_CHANNEL_WRONG_REPOSITORY。FILE现在已弃用该设置,它TABLE是默认设置。 -
必须将其设置为
TABLE。如果将此变量设置为FILE,则尝试向副本添加更多源失败ER_SLAVE_NEW_CHANNEL_WRONG_REPOSITORY。FILE现在已弃用该设置,它TABLE是默认设置。skip_slave_start=1该参数能够让数据库实例在启动的时候禁止建立主从关系,即禁止开启mysql的io线程和sql线程,用于搭建从库的时候需要,防止数据库启动的时候会自动开启了这两个线程,进而导致破坏了从库
因此在mysql的配置文件中的mysqld栏上加上该参数可防止破坏
当启用
enforce_gtid_consistency功能的时候,MySQL只允许能够保障事务安全,并且能够被日志记录的SQL语句被执行,像create table … select 和 create temporary table语句,以及同时更新事务表和非事务表的SQL语句或事务都不允许执行
binlog有三种模式:Row、Statement 和 Mixed 。
现在,以下启动选项会影响 复制拓扑中的所有通道。
master 1 主服务器ip:192.168.224.10
master 2 主服务器ip:192.168.224.12
slave 从服务器IP:192.168.224.11
master端
gtid-mode=on # 是否开启多源同步技术
enforce-gtid-consistency=1
skip_slave_start=1
log-bin=mysql-bin
server-id=1 # 指定mysql主从ID(该ID在主从集群中是唯一的)
slave端
server-id=3 # 指定mysql主从ID(该ID在主从集群中是唯一的)
gtid-mode = on # 是否开启多源同步技术
binlog_gtid_simple_recovery=1
enforce_gtid_consistency=1
master_info_repository=TABLE
relay_log_info_repository=TABLE
replicate_ignore_db=mysql
skip_slave_start = 1
一、配置文件
Master1和Master2:
1 | #GTID |
Slave:
1 | #binlog |
分别重启数据库
二、主库创建复制账号:
先创建用户和密码
master1
1 | create user 'aa1'@'%' identified with mysql_native_password by '123.Shui!!@#'; |
再授权
1 | grant replication slave,replication client on *.* to 'aa1'@'%'; |
master2
1 | create user 'aa2'@'%' identified with mysql_native_password by '123.Shui!!@#'; |
slave 测试能否连接
1 | mysql -u aa1 -h 192.168.224.10 -p'123.Shui!!@#' |
三:从库启动复制
1 | mysql> stop slave; |
也可以start slave for channel ‘Master_1 ‘启动单个channel的复制。
四:查看slave状态
也可以直接show slave status for channel ‘Master_1’ \G查看各个channel的复制状态
1 | show slave status for channel 'Master_1' \G |
通过查看performance_schema相关的表查看同步状态:
1 | select * from performance_schema.replication_connection_status\G |
五、数据同步检查:
Master1建库建表并插入数据:
1 | mysql> create database master1; |
Master2建库建表并插入数据:
1 | mysql> create database master2; |
Slave查看数据是否同步:
1 | mysql> show databases; |
查看从库的状态
1 | mysql> show slave status\G |
Mysql复制技术 之 半同步技术
这个技术是Mysql5.5版本之后的新功能。
前面我们学到的MySQL复制技术,是叫异步技术:
异步技术的概述:
在主服务器上每执行完一条事务命令后都会写进二进制的日志,从服务器通过IO线程监控主服务器的二进制日志,每当主服务器的二进制日志发生改变,从服务器就会启动复制
异步技术的特点:
是允许主从之间的数据存在一定的延迟,对网络要求不高,这样设计的目的是基于数据库的高可用性,为了保证master不受slave的影响,并且异步复制使得master处于一种性能最优的状态
缺点:
在主从架构中使用异步技术,如果master停机,会发生刚刚已提交的事务,slave未能及时复制过来的可能。
半同步技术特点:
master每操作一个事务,要等待slave应用这个事物后给master确认信号。这样master才能把操作成功执行。这样保证了主从数据的绝对一致,mysql半同步复制等待时间超时后(默认时间为10秒),会自动转换成异步复制
下面开始配置半同步复制技术:
环境要求:
搭建好 mysql主从异步复制
1、在master上安装半同步插件
安装插件之前记得需要解锁unlock tables;
1 | install plugin rpl_semi_sync_master soname 'semisync_master.so'; |
备注:删除主服务器插件的方法
1 | uninstall plugin rpl_semi_sync_master; |
安装成功后,会查询出以下6项参数
1 | show global variables like 'rpl_semi_sync%'; |
1 | rpl_semi_sync_master_timeout #默认主等待从返回信息的超时间时间,10秒。 |
2、在slave上安装插件
1 |
|
备注:删除从服务器插件的方法
1 | uninstall plugin rpl_semi_sync_slave; |
从服务器安装成功后,会查询出以下
1 | show global variables like 'rpl_semi_sync%'; |
1 | +---------------------------------+-------+ |
3、在主服务器master开启半同步复制
1 | set global rpl_semi_sync_master_enabled=on; #开启命令 |
在master查看状态
1 | show global status like 'rpl_semi_sync%'; |
1 | +--------------------------------------------+-------+ |
4、在从服务器slave开启半同步复制
1 | set global rpl_semi_sync_slave_enabled=on; #开启命令 |
在slave上查看状态
1 | show global status like 'rpl_semi_sync%'; |
5、测试半同步:
在主服务器上往aaa.a1表里插入数据:
1 | create database aaa; |
1 | +--------------------------------------------+-------+ |
6、模拟错误,把slave上的mysql停掉
1 | systemctl stop mysqld |
再回到master上往aaa.a1表里插入数据。
1 | insert into aaa.a1 values (4); |
再查看半同步的状态
1 | show global status like 'rpl_semi_sync%'; |
1 | +--------------------------------------------+-------+ |
再次把slave启动。
1 | systemctl start mysqld |
1 | show global variables like 'rpl_semi_sync%'; |
1 | +---------------------------------+-------+ |
再执行下开启动作,才可以重新打开半同步复制模式。
1 | set global rpl_semi_sync_slave_enabled=on; |
slave启起来后,查看表,发现刚才slave关闭期间的那几条数据还是会自动复制过来,数据又回到一致
思考题:
半同步技术模式:
在主服务器上只要执行:
1 | set global rpl_semi_sync_master_enabled=on; 这条语句就能开启 |
在从服务器上只要执行以下3条命令能就开启
1 | set global rpl_semi_sync_slave_enabled=on; |
一但主服务器或从服务器mysql服务停止或重启,半同步就会失效,有什么办法可以让他永久生效。
mysql的延时复制
延迟的复制特点:
可自行设置复制间隔时间,可以防止主节点数据误删,查看数据库历史状态等
在MySQL 的主从复制基础上操作:
命令语法:CHANGE MASTER TO MASTER_DELAY = 30; #设置备节点延迟的时间,单位秒。
1 | change master to master_user='aa1',master_password='123.Shui!!@#',master_host='192.168.224.10',master_log_file='mysql-bin.000001',master_log_pos=1663,master_delay=30; |
在slave从服务器上操作:
1、在slave从服务器上将slave服务停止
1 | stop slave; |
2、配置延迟复制时间,不用重新配置,直接添加下面这个语法就可以了
1 | change master to master_delay=30; |
3、启动slave线程
1 | start slave; |
4、查看状态
1 | show slave status\G |
已经将延时0秒变成了延时30秒。
5、测试,在master主服务器上插入1条数据
1 | insert into aaa.a1 values(6); |
回到slave从服务器上查询主刚插入的数据:
1 | select * from aaa.a1; |
主服务器插入完成后,马上回到从服务器查询是查询不到的,要等待30秒过后才可以
补充:mysql二进制日志管理
查看所有二进制日志:
1、直接查看数据目录下的文件
2、使用SQL语句:
1 | show binary logs; |
二进制日志滚动:
1、每次重启MySQL都会促发一次二进制日志滚动,文件后缀名+1
2、手动滚动;可使用 flush logs语句,执行后,二进制日志将会发生一次滚动,后缀名+1
1 | mysql> flush logs; |
二进制日志清除:
1、按文件名删除
1 |
|
2、按时间段删除
1 | mysql> purge binary logs before '2020-07-19 19:45'; |
作业题:
思考题:
假设在A上误删除一条数据,用二进制日志来恢复不太方便,因为日志里记录的是删除的操作,并没有记录这条数据具体是什么,所以你要在所有的日志里找到当初插入这条数据时的记录,这是很麻烦的。
原理理解题:
题1: mysql架构中,一主多从、双主、级联这三种的区别和优缺点
题2: 某公司mysql数据库运行了一年,现在要求搭建mysqlAB复制,检查主库后,发现它这一年没有使用二进制日志,请问如何做复制?
题3: 在实际大数据量的数据库中,因为负载太高或者网络问题,造成主从复制时有延时,此时你是DBA,请问如何处理?
题4: 如果一个lamp架构在深圳机房在运行,如何尽量无影响的把这个lamp迁移到惠州的机房
1,在惠州机房做一个lamp,mysql双主架构,web做rsync远程实时同步
2,把网站域名对应的IP地址A记录改成惠州的IP
3,当深圳机房服务器无连接时,就可以关闭深圳机房的服务器了
- 本文标题:mysql复制技术
- 本文作者:yichen
- 本文链接:https://yc6.cool/2020/08/03/mysql复制技术/
- 版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!

