Prometheus监控nginx,redis,rabbitmq,mongodb,docker等。 一、环境介绍
主机名
ip地址
系统
说明
localhost
192.168.224.11
centos7.8
docker方式安装Prometheus。
server2.com
192.168.224.12
centos7.8
mongo版本4.2.5,rabbitmq版本3.7.15,redis版本5,nginx版本1.21.6,docker版本23.01
1、环境搭建 安装docker和docker-compose
a、创建nginx目录 1 2 mkdir /data/nginx/conf.d -p cd /data/nginx/conf.d
在/data/nginx/conf.d目录里面新增加nginx的配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 cat >>server.conf<< "EOF" server { listen 80; server_name localhost; location / { root /usr/share/nginx/html; index index.html index.htm; } error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } } EOF
检查
b、docker-compose安装rabbitmq,nginx,mongo,redis 1 2 mkdir /data/docker-compose -p cd /data/docker-compose
通过cat 创建docker-compose.yaml⽂件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 cat > docker-compose.yaml <<"EOF" version: '3' services: redis: image: redis:5 container_name: redis command: redis-server --requirepass 123456 --maxmemory 512mb restart: always volumes: - /data/redis/data:/data ports: - 6379 :6379 nginx: image: nginx:1.21.6 container_name: nginx restart: always volumes: - /data/nginx/conf.d:/etc/nginx/conf.d - /data/nginx/html:/usr/share/nginx/html - /data/nginx/log:/var/log/nginx ports: - 80 :80 rabbitmq: image: rabbitmq:3.7.15-management container_name: rabbitmq restart: always volumes: - /data/rabbitmq/data:/var/lib/rabbitmq - /data/rabbitmq/log:/var/log/rabbitmq ports: - 5672 :5672 - 15672 :15672 mongo: image: mongo:4.2.5 container_name: mongo restart: always volumes: - /data/mongo/db:/data/db ports: - 27017 :27017 command: [--auth] environment: MONGO_INITDB_ROOT_USERNAME: root MONGO_INITDB_ROOT_PASSWORD: 123456 EOF
运行
检查
STATUS列全部为up为正常。
二、监控nginx nginx开启stu_status 监控nginx需要with-http_stub_status_module
检查是否安装有with-http_stub_status_module模块
1 sdocker exec -it nginx nginx -V 2>&1 | grep -o with-http_stub_status_module
nginx开启stub_status配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 cd /data/nginx/conf.d vim server.conf server { .... location /stub_status { stub_status on; access_log off; #allow nginx_export的ip; allow 0.0.0.0/0; deny all; } .... }
检查配置文件
1 docker exec -it nginx nginx -t
重新加载配置⽂件
1 docker exec -it nginx nginx -s reload
查看
1 curl http://192.168.224.12/stub_status
参数解释:
Active connections – 活动连接数
accepts – 接收请求数
handled – 成功处理请求数
requests – 总请求数
reding – 正在进⾏读操作的请求数
writing – 正在进⾏写操作的请求数
waiting – 正在等待的请求数
1、二进制安装nginx_exporter 1 nginx_exporter下载地址: https://github.com/nginxinc/nginx-prometheus-exporter/releases
下载⼆进制包解压并放⼊**/usr/local/Prometheus**⽬录
1 2 3 4 5 6 wget https://github.com/nginxinc/nginx-prometheus-exporter/releases/download/v0.11.0/nginx-prometheus-exporter_0.11.0_linux_amd64.tar.gz mkdir /usr/local/Prometheus/nginx_exporter -p tar xvf nginx-prometheus-exporter_0.11.0_linux_amd64.tar.gz -C /usr/local/Prometheus/nginx_exporter ls /usr/local/Prometheus/nginx_exporter/
创建⽤户
1 useradd -M -s /usr/sbin/nologin prometheus
更改exporter文件夹权限
1 chown prometheus:prometheus -R /usr/local/Prometheus
创建 systemd 服务
nginx_exporter.service
1 2 3 4 5 6 7 8 9 10 11 12 13 cat > /etc/systemd/system/nginx_exporter.service <<"EOF" [Unit] Description=nginx-prometheus-exporter After=network.target [Service] Type=simple User=prometheus Group=prometheus Restart=always ExecStart=/usr/local/Prometheus/nginx_exporter/nginx-prometheus-exporter -nginx.scrape-uri=http://192.168.224.12/stub_status [Install] WantedBy=multi-user.target EOF
启动 nginx_exporter
1 2 3 4 systemctl daemon-reload systemctl start nginx_exporter.service systemctl enable nginx_exporter.service systemctl status nginx_exporter.service
启动不了检查⽇志
1 journalctl -u nginx_exporter.service -f
2、docker安装nginx_exporter docker-compose方式
通过cat创建⽂件
1 2 3 4 5 6 7 8 9 10 11 12 13 cat >docker-compose.yaml <<EOF version: '3.3' services: nginx_exporter: image: nginx/nginx-prometheus-exporter:0.11 container_name: nginx_exporter hostname: nginx_exporter command: - '-nginx.scrape-uri=http://192.168.224.12/stub_status' restart: always ports: - "9113:9113" EOF
启动
检查
1 2 3 docker ps -a 或: docker logs -f nginx_exporter
3 、参数解释
Environment variable 命令⾏参数
description
-nginx.scrape-uri
nginx stub_status 复制
4 、metrics 地址注:安装好Exporter后会暴露⼀个 http://ip:端⼝/metrics 的HTTP服务
名称
地址
nginx_exporter
http://192.168.224.12:9113/metrics
5 、Prometheus 配置配置prometheus去采集(拉取)nginx_exporter的监控样本数据
1 2 3 4 5 6 7 8 9 10 cd /data/docker-prometheus #在scrape_configs(搜刮配置):下⾯增加如下配置: cat >> prometheus/prometheus.yml << "EOF" - job_name: 'nginx_exporter' static_configs: - targets: ['192.168.224.12:9113'] labels: instance: server2.com服务器 EOF
重新加载配置
1 curl -X POST http://localhost:9090/-/reload
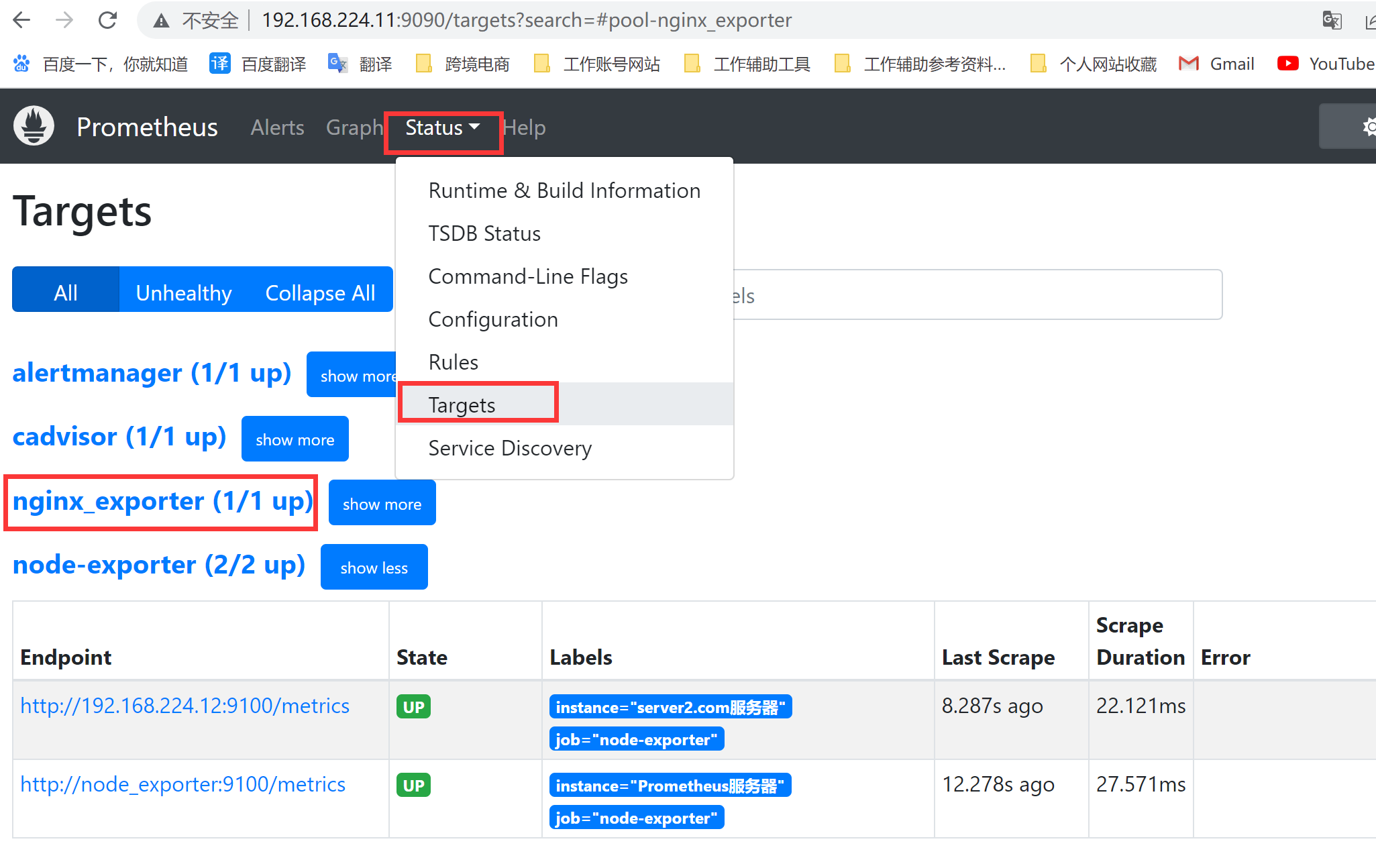
检查
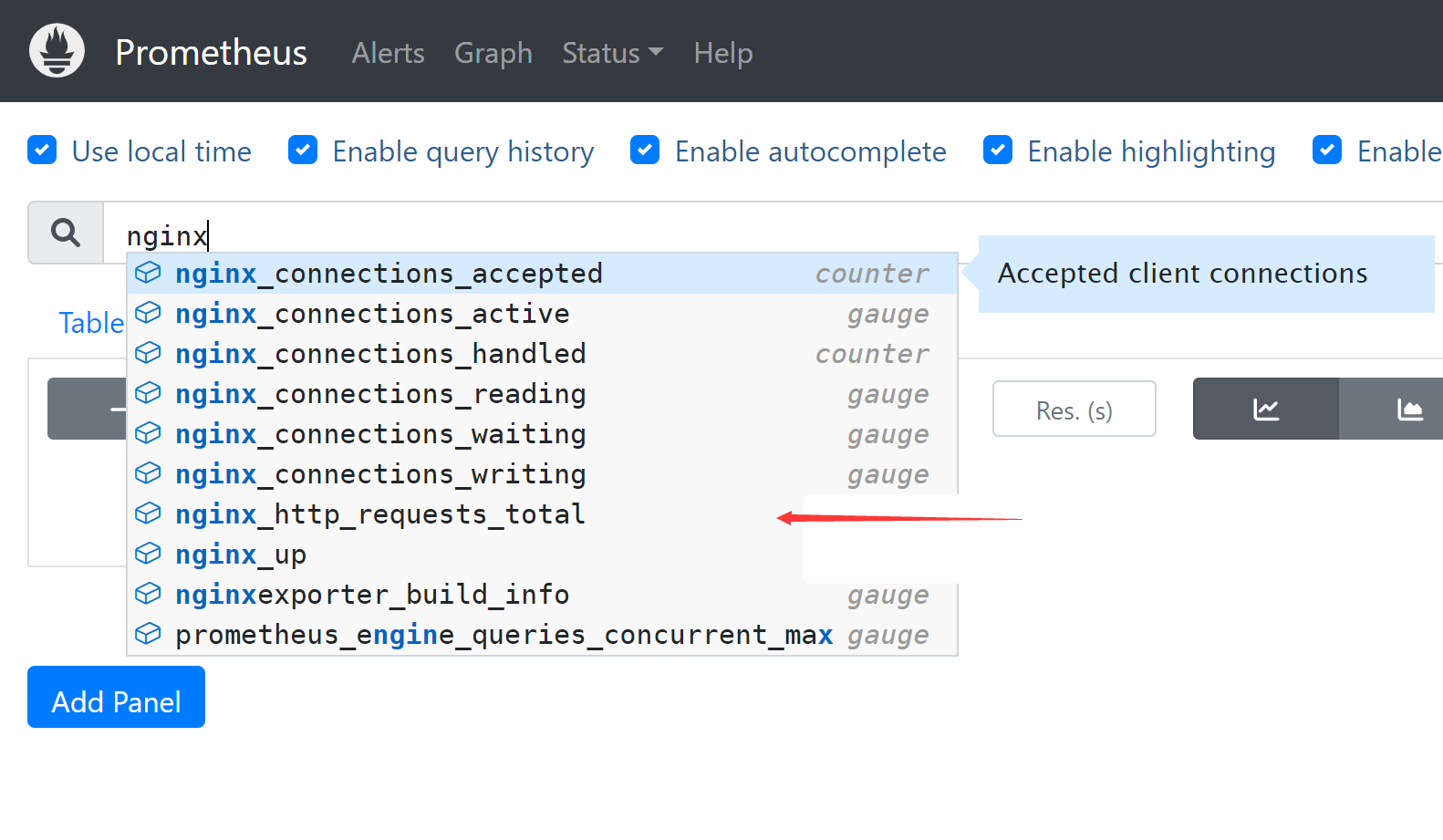
6 、常⽤的监控指标1 2 3 4 5 6 7 nginx_connections_accepted 接收请求数 nginx_connections_active 活动连接数 nginx_connections_handled 成功处理请求数 nginx_connections_reding 正在进⾏读操作的请求数 nginx_connections_waiting 正在等待的请求数 nginx_connections_writing 正在进⾏写操作的请求数 nginx_connections_requests 总请求数
7 、添加触发器1 cd /data/docker-prometheus
追加以下信息
1 2 3 4 5 6 7 8 9 10 11 12 13 cat >>prometheus/alert.yml <<"EOF" - name: nginx rules: # 对任何实例超过30秒无法联系的情况发出警报 - alert: NginxDown expr: nginx_up == 0 for: 30s labels: severity: critical annotations: summary: "nginx异常,实例:{{ $labels.instance }}" description: "{{ $labels.job }} nginx已关闭" EOF
检查
1 vim prometheus/alert.yml
检查配置
1 docker exec -it prometheus promtool check config /etc/prometheus/prometheus.yml
重新加载配置
1 curl -X POST http://localhost:9090/-/reload
检查
1 2 3 http://192.168.224.11:9090/alerts?search= 或者 http://192.168.224.11:9090/rules
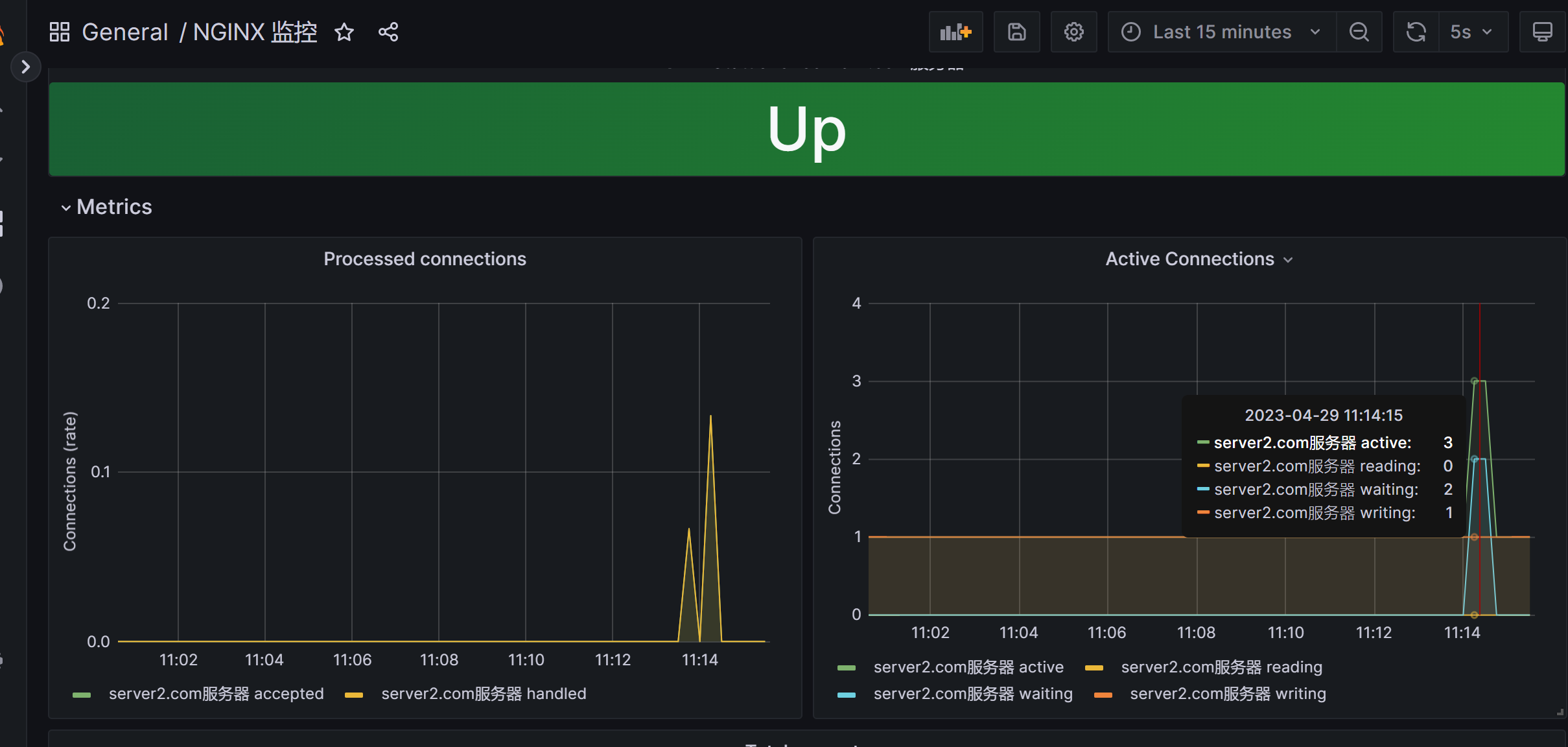
8 、dashboard grafana展示prometheus从nginx_exporter收集到的的数据
1 https://grafana.com/grafana/dashboards/12708
直接导入模板即可。后面的效果
三、监控redis redis已经在上面通过docker-compose部署好了
1、二进制安装redis_exporter redis_exporter下载地址
1 https://github.com/oliver006/redis_exporter/releases
下载⼆进制包解压并放⼊**/usr/local/Prometheus**⽬录
1 2 3 4 5 wget https://github.com/oliver006/redis_exporter/releases/download/v1.48.0/redis_exporter-v1.48.0.linux-amd64.tar.gz tar xvf redis_exporter-v1.48.0.linux-amd64.tar.gz mv redis_exporter-v1.48.0.linux-amd64 /usr/local/Prometheus/redis_exporter
创建⽤户(前面已经创建了就不用创建了)
1 useradd -M -s /usr/sbin/nologin prometheus
更改exporter ⽂件夹权限
1 chown prometheus:prometheus -R /usr/local/Prometheus/
创建 systemd 服务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 cat > /etc/systemd/system/redis_exporter.service <<"EOF" [Unit] Description=Prometheus Redis Exporter After=network.target [Service] Type=simple User=prometheus Group=prometheus Restart=always ExecStart=/usr/local/Prometheus/redis_exporter/redis_exporter \ -redis.addr localhost:6379 \ -redis.password 123456 [Install] WantedBy=multi-user.target EOF
启动 redis_exporter
1 2 3 4 systemctl daemon-reload systemctl start redis_exporter systemctl enable redis_exporter systemctl status nredis_exporter
启动不了检查⽇志
1 journalctl -u redis_exporter -f
2、docker安装redis_exporter docker直接运行
1 docker run -d --restart=always --name redis_exporter -p 9121:9121 oliver006/redis_exporter --redis.addr redis://192.168.224.12:6379 --redis.password '123456'
docker-compose ⽅式
1 2 3 4 5 6 7 8 9 10 11 12 13 cat >docker-compose.yaml <<EOF version: '3.3' services: redis_exporter: image: oliver006/redis_exporter container_name: redis_exporter restart: always environment: REDIS_ADDR: "192.168.224.12:6379" REDIS_PASSWORD: 123456 ports: - "9121:9121" EOF
启动
检查
1 2 3 docker ps -a 或: docker logs -f redis_exporter
3、参数解释
Environment variable
值
description
REDIS_ADDR
192.168.224.12:6379
redis服务器地址,如:ip:6379
REDIS_PASSWORD
123456
redis服务器管理密码
4 、metrics 地址注:安装好Exporter后会暴露⼀个 http://ip:端⼝/metrics 的HTTP服务
名称
地址
redis_exporter
http://192.168.224.12:9121/metrics
5 、Prometheus 配置配置prometheus去采集(拉取)redis_exporter的监控样本数据
1 2 3 4 5 6 7 8 9 10 cd /data/docker-prometheus #在scrape_configs(搜刮配置):下⾯增加如下配置: cat >> prometheus/prometheus.yml << "EOF" - job_name: 'redis_exporter' static_configs: - targets: ['192.168.224.12:9121'] labels: instance: server2.com服务器 EOF
重新加载配置
1 curl -X POST http://localhost:9090/-/reload
6 、常⽤的监控指标1 2 3 4 5 6 7 8 9 10 11 12 redis_up # 服务器是否在线 redis_uptime_in_seconds # 运⾏时⻓,单位 s rate(redis_cpu_sys_seconds_total[1m]) + rate(redis_cpu_user_seconds_total[1m]) # 占⽤ CPU 核数 redis_memory_used_bytes # 占⽤内存量 redis_memory_max_bytes # 限制的最⼤内存,如果没限制则为 0 delta(redis_net_input_bytes_total[1m]) # ⽹络接收的 bytes delta(redis_net_output_bytes_total[1m]) # ⽹络发送的 bytes redis_connected_clients # 客户端连接数 redis_connected_clients / redis_config_maxclients # 连接数使⽤率 redis_rejected_connections_total # 拒绝的客户端连接数 redis_connected_slaves # slave 连接数
7 、触发器配置Prometheus配置
1 2 3 4 5 6 vim prometheus/prometheus.yml # 报警(触发器)配置 rule_files: - "alert.yml" - "rules/*.yml"
创建新目录
redis 触发器(告警规则)
因为是单机,所以未配置集群的触发器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 cat >> prometheus/rules/redis.yml <<"EOF" groups: - name: redis rules: - alert: RedisDown expr: redis_up == 0 for: 0m labels: severity: critical annotations: summary: 'Redis Down,实例:{{ $labels.instance }}' description: "Redis实例 is down" - alert: RedisMissingBackup expr: time() - redis_rdb_last_save_timestamp_seconds > 60 * 60 * 24 for: 0m labels: severity: critical annotations: summary: "Redis备份丢失,实例:{{ $labels.instance }}" description: "Redis 24⼩时未备份" - alert: RedisOutOfConfiguredMaxmemory expr: redis_memory_used_bytes / redis_memory_max_bytes * 100 > 90 for: 2m labels: severity: warning annotations: summary: "Redis超出配置的最⼤内存,实例:{{ $labels.instance }}" description: "Redis内存使⽤超过配置最⼤内存的90%" - alert: RedisTooManyConnections expr: redis_connected_clients > 100 for: 2m labels: severity: warning annotations: summary: "Redis连接数过多,实例:{{ $labels.instance }}" description: "Redis当前连接数为: {{ $value }}" - alert: RedisNotEnoughConnections expr: redis_connected_clients < 1 for: 2m labels: severity: warning annotations: summary: "Redis没有⾜够的连接,实例:{{ $labels.instance }}" description: "Redis当前连接数为: {{ $value }}" - alert: RedisRejectedConnections expr: increase(redis_rejected_connections_total[1m]) > 0 for: 0m labels: severity: critical annotations: summary: "Redis有拒绝连接,实例:{{ $labels.instance }}" description: "与Redis 的某些连接被拒绝{{ $value }}" EOF
检查配置
1 docker exec -it prometheus promtool check config /etc/prometheus/prometheus.yml
重新加载配置
1 curl -X POST http://localhost:9090/-/reload
检查
1 http://192.168.224.11:9090/alerts?search=
8 、dashboard grafana展示prometheus从redis_exporter收集到的的数据
1 2 3 4 Redis: https://grafana.com/grafana/dashboards/11835 或者 https://grafana.com/grafana/dashboards/17507
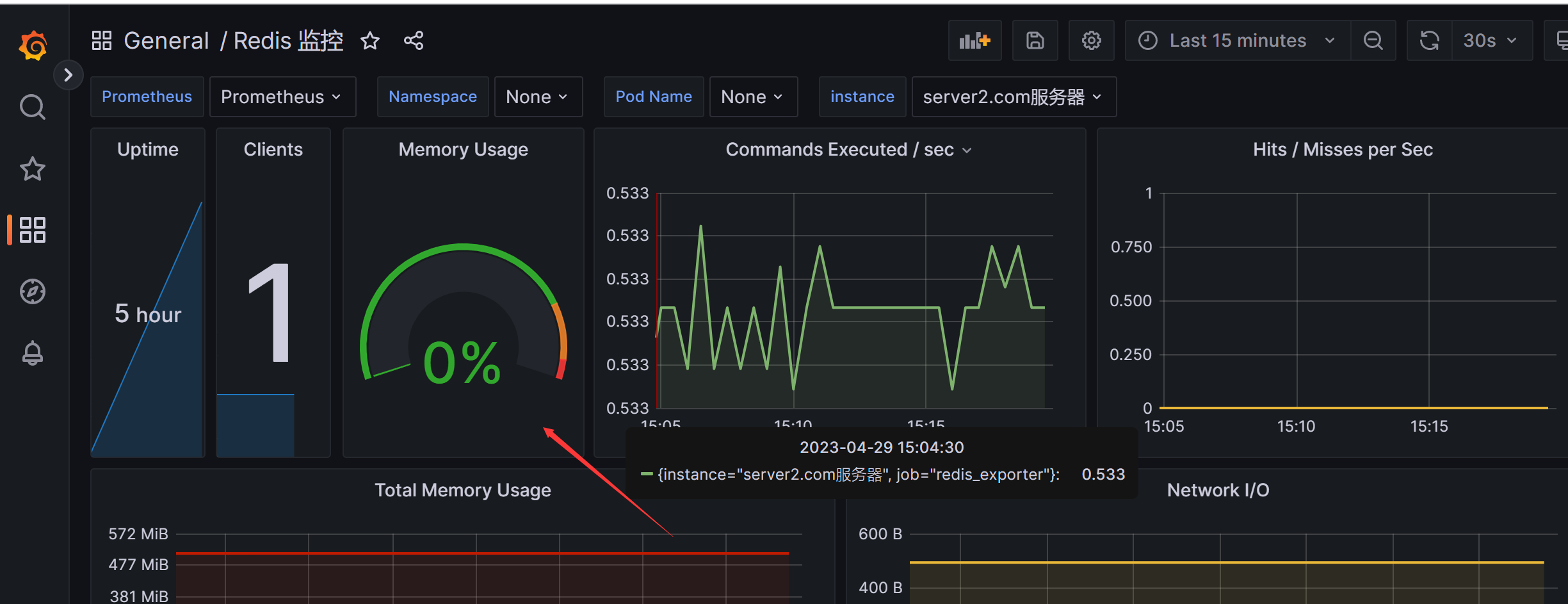
图⾏展示问题
redis dashbord 内存使⽤图⾏展示有问题,如下图
http://192.168.224.11:9090/graph
查询到 redis_memory_max_bytes 为0,因为redis配置参数 maxmemory 未设置,默认 0 。
解决
四、监控rabbitmq rabbitmq已经在安装Nginx时,通过docker-compose部署好了
1、二进制安装rabbitmq_exporter rabbit_exporter下载地址:
1 https://github.com/kbudde/rabbitmq_exporter/releases
下载⼆进制包解压并放⼊**/usr/local/Prometheus**⽬录
1 2 3 4 wget https://github.com/kbudde/rabbitmq_exporter/releases/download/v1.0.0-RC19/rabbitmq_exporter_1.0.0-RC19_linux_amd64.tar.gz mkdir /usr/local/Prometheus/rabbitmq_exporter tar xzf rabbitmq_exporter_1.0.0-RC19_linux_amd64.tar.gz -C /usr/local/Prometheus/rabbitmq_exporter/
更改权限
1 chown prometheus.prometheus -R /usr/local/Prometheus/
创建systemd服务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 cat > /etc/systemd/system/rabbitmq_exporter.service <<"EOF" [Unit] Description=Prometheus rabbitmq Exporter After=network.target [Service] Environment=RABBIT_USER=guest Environment=RABBIT_PASSWORD=guest Environment=RABBIT_URL=http://localhost:15672 OUTPUT_FORMAT=JSON Type=simple User=prometheus Group=prometheus Restart=always ExecStart=/usr/local/Prometheus/rabbitmq_exporter/rabbitmq_exporter [Install] WantedBy=multi-user.target EOF
启动
1 2 3 4 systemctl daemon-reload systemctl start rabbitmq_exporter systemctl enable rabbitmq_exporter systemctl status rabbitmq_exporter
启动不了检查日志
1 journalctl -u rabbitmq_exporter -f
2、docker安装rabbitmq_exporter docker直接运行
1 docker run -d -p 9419:9419 --name rabbitmq_exporter -e RABBIT_URL=http://192.168.224.12:15672 -e RABBIT_USER=guest -e RABBIT_PASSWORD=guest kbudde/rabbitmq-exporter
docker-compose方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 cat >docker-compose.yaml <<EOF version: '3.3' services: rabbitmq_exporter: image: kbudde/rabbitmq-exporter container_name: rabbitmq_exporter restart: always environment: RABBIT_URL: "http://192.168.224.12:15672" RABBIT_USER: "guest" RABBIT_PASSWORD: "guest" PUBLISH_PORT: "9419" OUTPUT_FORMAT: "JSON" ports: - "9419:9419" EOF
启动
检查
3、参数解释
Environment variable
default
description
RABBIT_URL
http://127.0.0.1:15672rabbitMQ管理插件的url(必须以http(s)开头)
RABBIT_USER
guest
rabbitMQ管理插件的用户名
RABBIT_PASSWORD
guest
rabbitMQ管理插件的密码
OUTPUT_FORMAT
JOSN
输出格式
PUBLISH_PORT
9419
运行端口(监听端口)
4、metrics地址 注:安装好Exporter后会暴露⼀个 http://ip:端⼝/metrics 的HTTP服务
名称
地址
rabbitmq_exporter
http://192.168.224.12:9419/metrics
5、Prometheus配置 配置prometheus去采集(拉取)rabbitmq_exporter的监控样本数据
1 2 3 4 5 6 7 8 9 10 cd /data/docker-prometheus #在scrape_configs(搜刮配置):下⾯增加如下配置: cat >> prometheus/prometheus.yml << "EOF" - job_name: 'rabbitmq_exporter' static_configs: - targets: ['192.168.224.12:9419'] labels: instance: server2.com服务器 EOF
重新加载配置
1 curl -X POST http://localhost:9090/-/reload
6 、常⽤的监控指标1 2 3 4 5 6 7 8 9 10 11 12 rabbitmq_queue_messages_unacknowledged_global 队列中有未确认的消息总数(未被消费的消息) rabbitmq_node_disk_free_limit 使用磁盘大小 rabbitmq_node_disk_free 磁盘总大小 rabbit_node_mem_used 使用内存大小 rabbit_node_mem_limit 内存总大小 rabbitmq_sockets_used 使用sockets数量 rabbitmq_sockets_available 可用的sockets总数 rabbitmq_fd_used 使用文件描述符的数量 rabbitmq_fd_available 可用的文件描述符总数
7、触发器配置 Rabbitmq触发器
也是单节点,未配置集群触发器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 cat >> prometheus/rules/rabbitmq.yml <<"EOF" groups: - name: Rabbitmq rules: - alert: RabbitMQDown expr: rabbitmq_up != 1 labels: severity: High annotations: summary: "Rabbitmq Down,实例:{{ $labels.instance }}" description: "Rabbitmq_exporter连不上RabbitMQ! ! !" - alert: RabbitMQ有未确认消息 expr: rabbitmq_queue_messages_unacknowledged_global > 0 for: 1m labels: severity: critical annotations: summary: "RabbitMQ有未确认消息,实例:{{ $labels.instance }}" description: 'RabbitMQ未确认消息>0,当前值为:{{ $value }}' - alert: RabbitMQ可用磁盘空间不足告警 expr: rabbitmq_node_disk_free_alarm != 0 #expr: rabbitmq_node_disk_free_limit / rabbitmq_node_disk_free *100 > 90 for: 0m labels: severity: critical annotations: summary: "RabbitMQ可用磁盘空间不足,实例:{{ $labels.instance }}" description: "RabbitMQ可用磁盘空间不足,请检查" - alert: RabbitMQ可用内存不足告警 expr: rabbitmq_node_mem_alarm != 0 #expr: rabbitmq_node_mem_used / rabbitmq_node_mem_limit * 100 > 90 for: 0m labels: severity: critical annotations: summary: "RabbitMQ可用内存不足,实例:{{ $labels.instance }}" description: "RabbitMQ可用内存不足,请检查" - alert: RabbitMQ_socket连接数使用过高告警 expr: rabbitmq_sockets_used / rabbitmq_sockets_available * 100 > 60 for: 0m labels: severity: critical annotations: summary: "RabbitMQ_socket连接数使用过高,实例:{{ $labels.instance }}" description: 'RabbitMQ_sockets使用>60%,当前值为:{{ $value }}' - alert: RabbitMQ文件描述符使用过高告警 expr: rabbitmq_fd_used / rabbitmq_fd_available * 100 > 60 for: 0m labels: severity: critical annotations: summary: "RabbitMQ文件描述符使用过高,实例:{{ $labels.instance }}" description: 'RabbitMQ文件描述符使用>60%,当前值为:{{ $value }}' EOF
检查配置
1 docker exec -it prometheus promtool check config /etc/prometheus/prometheus.yml
重新加载配置
1 curl -X POST http://localhost:9090/-/reload
检查
1 http://192.168.224.11:9090/alerts?search=
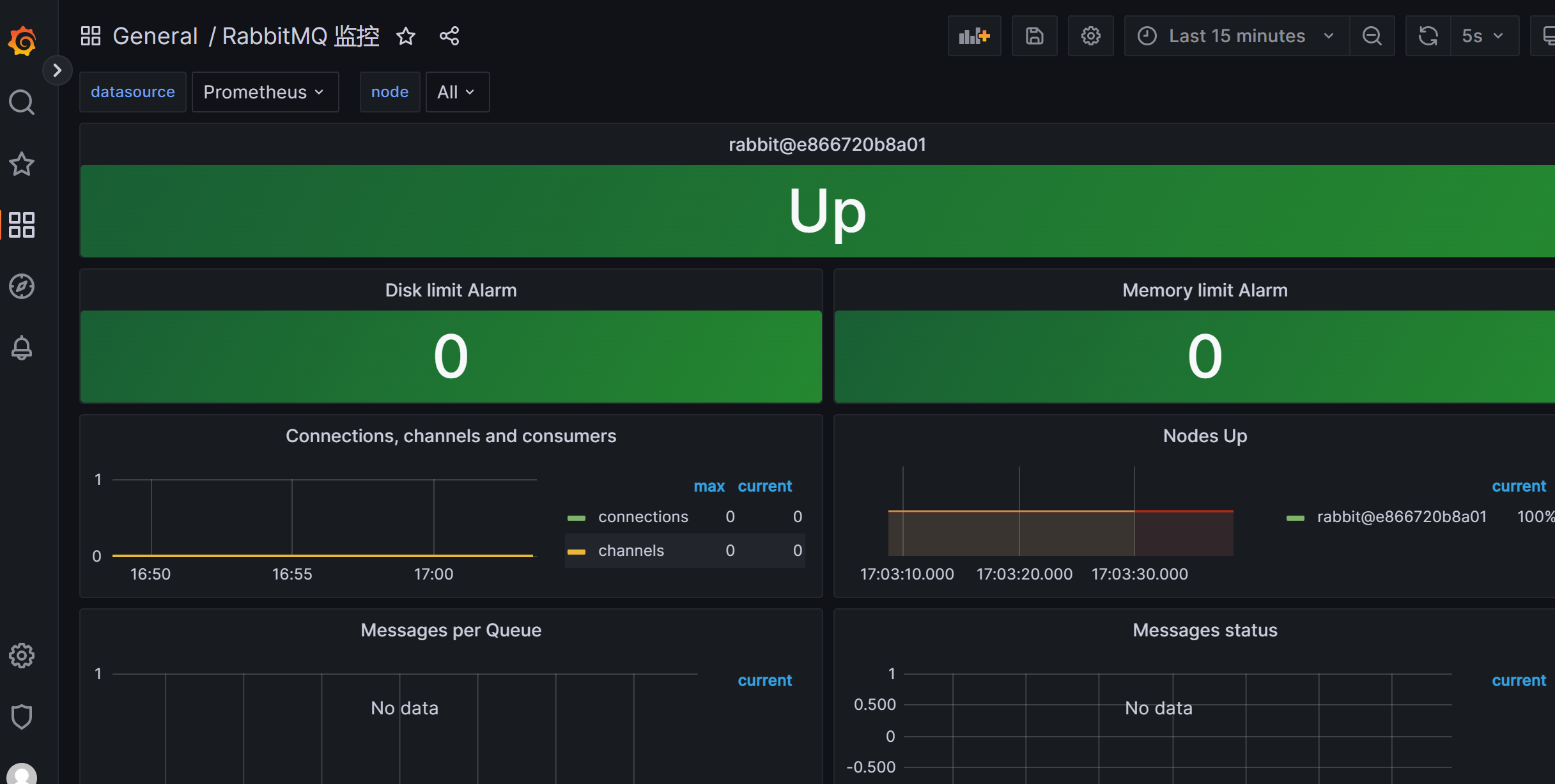
8 、dashboard grafana展示prometheus从rabbitmq_exporter收集到的的数据
id: 4279
1 https://grafana.com/grafana/dashboards/4279-rabbitmq-monitoring/
五、监控mongodb 1 、创建监控⽤户登陆mongodb创建监控⽤户,权限为“readAnyDatabase”,如果是cluster环境,需要有权限“clusterMonitor”
登录mongodb(docker安装的mongo)
1 docker exec -it mongo mongo admin
登录mongodb(yum和apt安装的mongo)
创建监控用户
1 2 3 4 5 6 7 8 > db.auth('root','123456') 1 > db.createUser({ user:'exporter',pwd:'password',roles:[ { role:'readAnyDatabase', db: 'admin'},{ role: "clusterMonitor", db: "admin" }]}); #测试 使⽤上⾯创建的⽤户信息进⾏连接。 > db.auth('exporter', 'password') 1 #表示成功 > exit
2、二进制安装mongodb_expoter mongodb_exporter地址
1 2 3 https://github.com/percona/mongodb_exporter/releases 或者 https://github.com/prometheus/mysqld_exporter/releases
下载⼆进制包解压并放⼊**/usr/local/Prometheus**⽬录
1 2 3 4 5 wget https://github.com/percona/mongodb_exporter/releases/download/v0.37.0/mongodb_exporter-0.37.0.linux-amd64.tar.gz tar xzf mongodb_exporter-0.37.0.linux-amd64.tar.gz mv mongodb_exporter-0.37.0.linux-amd64 /usr/local/Prometheus/mongodb_exporter
更改exporter ⽂件夹权限
1 chown prometheus.prometheus -R /usr/local/Prometheus/
创建 systemd 服务
mongodb_exporter.service
1 2 3 4 5 6 7 8 9 10 11 12 13 14 cat <<EOF >/usr/lib/systemd/system/mongodb_exporter.service [Unit] Description=mongodb_exporter Documentation=https://github.com/percona/mongodb_exporter After=network.target [Service] Type=simple User=prometheus Environment="MONGODB_URI=mongodb://exporter:password@localhost:27017/admin" ExecStart=/usr/local/Prometheus/mongodb_exporter/mongodb_exporter --log.level=error --collect-all --compatible-mode Restart=on-failure [Install] WantedBy=multi-user.target EOF
启动 mongodb_exporter
1 2 3 4 systemctl daemon-reload systemctl start mongodb_exporter.service systemctl enable mongodb_exporter.service systemctl status mongodb_exporter.service
启动不了检查⽇志
1 journalctl -u mongodb_exporter.service -f
3、docker安装mongodb_exporter docker 直接运⾏
1 docker run -d --restart=always -p 9216:9216 -p 17001:17001 --restart=always --name=mongodb-exporter bitnami/mongodb-exporter:latest --collect-all --compatible-mode --mongodb.uri=mongodb://exporter:password@192.168.224.12:27017/admin?ssl=false
docker-compose ⽅式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 cat >docker-compose.yaml <<EOF version: '3.3' services: mongodb_exporter: image: bitnami/mongodb-exporter:latest container_name: mongodb_exporter restart: always environment: MONGODB_URI: "mongodb://exporter:password@192.168.224.12:27017/admin?ssl=false" command: - '--collect-all' - '--compatible-mode' ports: - "9216:9216" EOF
启动
检查
4 、参数解释
Flag 含义
案例
-h, –help
显示上下⽂相关的帮助
–[no-]compatible-mode
启⽤旧的 mongodb exporter 兼容指标
–[no-]discovering-mode
启⽤⾃动发现集合
–mongodb.collstats-colls
逗号分隔的databases.collections列表以获取 $collStats
–mongodb.collstats-colls=db1,db2.col2
–mongodb.indexstats-colls
逗号分隔的databases.collections列表以获取$indexStats
–mongodb.indexstats-colls=db1.col1,db2.col2
–[no-]mongodb.direct-connect
是否应该进⾏直接连接。如果指定了多个主机或使⽤了 SRVURI,则直接连接⽆效
–[no-]mongodb.global-connpool
使⽤全局连接池⽽不是为每个http请求创建新池
–mongodb.uri
MongoDB 连接 URI($MONGODB_URI)
–smongodb.uri=mongodb://user:pass@127.0.0.1 :27017/admin?
–web.listen-address
⽤于侦听 Web 界⾯和遥测的地址
–web.listen-address=”:9216”
–web.telemetry-path
指标公开路径
–web.telemetry-path=”/metrics”
–web.config
具有⽤于基本身份验证的 Prometheus TLS配置的⽂件的路径
–web.config=STRING
–log.level
仅记录具有给定严重性或更⾼严重性的消息。有效级别:[调试、信息、警告、错误、致命]
–log.level=”erro
–collector.diagnosticdata
启⽤从getDiagnosticData收集指标
–collector.replicasetstatus
启⽤从replSetGetStatus 收集指标
–collector.dbstats
启⽤从 dbStats 收集指标
–collector.topmetrics
启⽤从 top admincommand 收集指标
–collector.indexstats
启⽤从 $indexStats收集指标
–collector.collstats
启⽤从 $collStats 收集指标
–collect-all
启⽤所有收集器。与指定所有 –collector.相同
–collector.collstats-limit=0
如果有超过 个集合,请禁⽤ collstats、dbstats、topmetrics和 indexstats 收集器。0=⽆限制
--metrics.overridedescendingindex
启⽤降序索引名称覆盖以将 -1 替换为_DESC
–version
显示版本并退出
5 、metrics 地址注:安装好Exporter后会暴露⼀个 http://ip:端⼝/metrics 的HTTP服务
名称
地址
rabbitmq_exporter
http://192.168.224.12:9216/metrics
6 、Prometheus 配置配置prometheus去采集(拉取)mongodb_exporter的监控样本数据
1 2 3 4 5 6 7 8 9 10 cd /data/docker-prometheus #在scrape_configs(搜刮配置):下⾯增加如下配置: cat >> prometheus/prometheus.yml << "EOF" - job_name: 'mongodb_exporter' static_configs: - targets: ['192.168.224.12:9216'] labels: instance: server2.com服务器 EOF
重新加载配置
1 curl -X POST http://localhost:9090/-/reload
检查
7 、常⽤的监控指标1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 mongodb_ss_connections{conn_type="available"} 可⽤的连接总数 mongodb_ss_mem_virtual mongodb_ss_mem_resident # 关于 server status mongodb_up # 服务器是否在线 mongodb_ss_ok{cl_id="", cl_role="mongod", rs_state="0"} # 服务器是否正常运⾏,取值为 1、0 。标签中记录了 Cluster、ReplicaSet 的信息 mongodb_ss_uptime # 服务器的运⾏时⻓,单位为秒 mongodb_ss_connections{conn_type="current"} # 客户端连接数 # 关于主机 mongodb_sys_cpu_num_cpus # 主机的 CPU 核数 # 关于 collection mongodb_collstats_storageStats_count{database="xx", collection="xx"} # collection 全部⽂档的数量 mongodb_collstats_storageStats_size # collection 全部⽂档的体积,单位 bytes mongodb_collstats_storageStats_storageSize # collection 全部⽂档占⽤的磁盘空间,默认会压缩 delta(mongodb_collstats_latencyStats_reads_ops[1m]) # collection 读操作的数量(每分钟) delta(mongodb_collstats_latencyStats_reads_latency[1m]) # collection 读操作的延迟(每分钟),单位为微秒 mongodb_collstats_latencyStats_write_ops mongodb_collstats_latencyStats_write_latency # 关于 index mongodb_collstats_storageStats_nindexes # collection 的 index 数量 mongodb_collstats_storageStats_totalIndexSize # collection 的 index 占⽤的磁盘空间 delta(mongodb_indexstats_accesses_ops[1m]) # index 被访问次数 # 关于操作 delta(mongodb_ss_opcounters[1m]) # 执⾏各种操作的数量 delta(mongodb_ss_opLatencies_latency[1m]) # 执⾏各种操作的延迟,单位为微秒 delta(mongodb_ss_metrics_document[1m]) # 各种⽂档的变化数量 # 关于锁 delta(mongodb_ss_locks_acquireCount{lock_mode="w"}[1m]) # 新加锁的数量。R 表示共享锁,W 表示独占锁,r表示意向共享锁,w 表示意向独占锁 mongodb_ss_globalLock_currentQueue{count_type="total"} # 被锁阻塞的操作数
8 、触发器配置mongodb 触发器(告警规则)
因mongo单点,所以未配置复制触发器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 cat >> prometheus/rules/mongodb.yml <<"EOF" groups: - name: PerconaMongodbExporter rules: - alert: MongodbDown expr: 'mongodb_up == 0' for: 0m labels: severity: critical annotations: summary: "MongoDB Down 容器: $labels.instance" description: "MongoDB 容器 is down, 当前值:{{ $value }}" - alert: MongodbNumberCursorsOpen expr: 'mongodb_ss_metrics_cursor_open{csr_type="total"} > 10 * 1000' for: 2m labels: severity: warning annotations: summary: "MongoDB 数字有标打开告警 容器: $labels.instance" description: "MongoDB 为客户端打开的游标过多 > 10k, 当前值:{{ $value }}" - alert: MongodbCursorsTimeouts expr: 'increase(mongodb_ss_metrics_cursor_timedOut[1m]) > 100' for: 2m labels: severity: warning annotations: summary: "MongoDB 游标超时 容器: $labels.instance" description: "太多游标超时, 当前值:{{ $value }}" - alert: MongodbTooManyConnections expr: 'avg by(instance) (rate(mongodb_ss_connections{conn_type="current"}[1m])) / avg by(instance) (sum (mongodb_ss_connections) by (instance)) * 100 > 80' for: 2m labels: severity: warning annotations: summary: "MongoDB 太多连接 容器: $labels.instance" description: "MongoDB 连接数 > 80%, 当前值:{{ $value }}" - alert: MongodbVirtualMemoryUsage expr: '(sum(mongodb_ss_mem_virtual) BY (instance) / sum(mongodb_ss_mem_resident) BY (instance)) > 3' for: 2m labels: severity: warning annotations: summary: "MongoDB虚拟内存使用告警 容器: $labels.instance" description: "虚拟内存使用过高, 当前值:{{ $value }}" EOF
检查配置
1 docker exec -it prometheus promtool check config /etc/prometheus/prometheus.yml
重新加载配置
1 curl -X POST http://localhost:9090/-/reload
检查
1 http://192.168.224.11:9090/alerts?search=
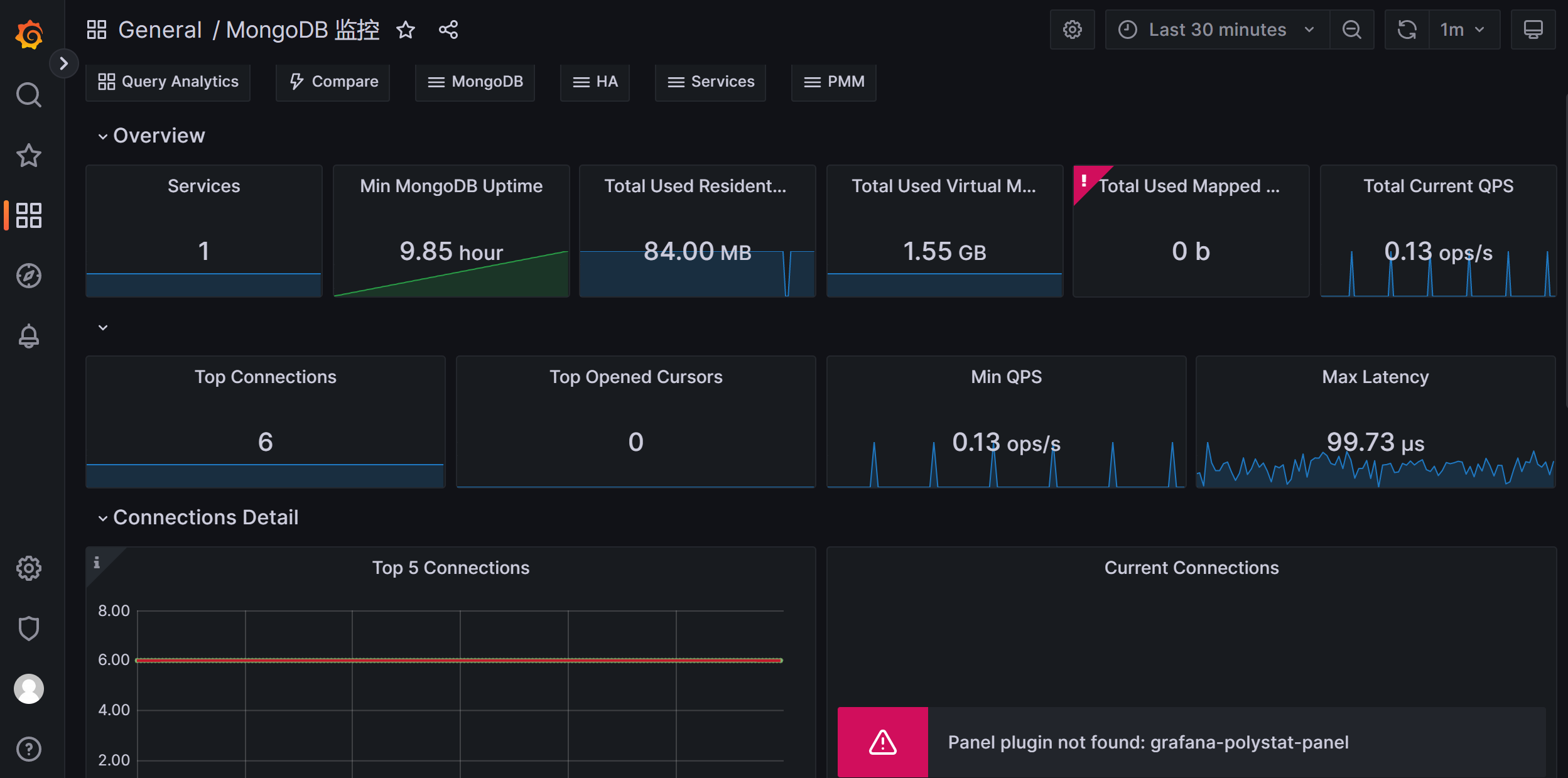
8 、dashboard grafana展示prometheus从mongodb_exporter收集到的的数据
1 2 3 4 https://github.com/percona/grafana-dashboards/tree/main/dashboards/MongoDB 下载这个MongoDB_Instances_Overview.json文件 导入到grafana
看到有报缺少插件,polystat,可以下载插件
到设置里面的Plugins里面搜索polystat,然后安装
六、监控docker 为了能够获取到Docker容器的运⾏状态,⽤户可以通过Docker的stats命令获取到当前主机上运⾏容器的
统计信息,可以查看容器的CPU利⽤率、内存使用量、网络IO总量以及磁盘IO总量等信息。
除了使⽤命令以外,⽤户还可以通过Docker提供的HTTP API查看容器详细的监控统计信息。
1、使⽤CAdvisor CAdvisor是Google开源的⼀款⽤于展示和分析容器运⾏状态的可视化⼯具。通过在主机上运⾏CAdvisor
⽤户可以轻松的获取到当前主机上容器的运⾏统计信息,并以图表的形式向⽤户展示。
docker 命令安装
1 2 3 4 5 6 7 8 9 docker run -d \ --restart=always \ --volume=/:/rootfs:ro \ --volume=/var/run:/var/run:rw \ --volume=/sys:/sys:ro \ --volume=/var/lib/docker/:/var/lib/docker:ro \ --publish=8080:8080 \ --name=cadvisor \ google/cadvisor:latest
Docker-compose 安装
1 2 mkdir /data/cadvisor cd /data/cadvisors
通过 cat新建 docker-compose.yaml⽂件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 cat > docker-compose.yaml <<"EOF" version: '3.3' services: cadvisor: image: google/cadvisor:latest container_name: cadvisor restart: always volumes: - /:/rootfs:ro - /var/run:/var/run:rw - /sys:/sys:ro - /var/lib/docker/:/var/lib/docker:ro ports: - 8080:8080 EOF
启动
1 2 3 4 docker-compose up -d docker ps
通过访问http://192.168.224.12:8080可以查看,当前主机上容器的运⾏状态,如下所示
访问http://192.168.224.12:8080/metrics即可获取到标准的Prometheus监控样本输出
2、Prometheus 配置 配置prometheus去采集(拉取)cAdvisor的监控样本数据
1 2 3 4 5 6 7 8 9 10 cd /data/docker-prometheus #在scrape_configs(搜刮配置):下⾯增加如下配置: cat >> prometheus/prometheus.yml << "EOF" - job_name: 'cadvisor' scrape_interval: 15s static_configs: - targets: ['192.168.224.12:8080'] labels: instance: server2.com服务器 EOF
重新加载配置
1 curl -X POST http://localhost:9090/-/reload
检查
启动完成后,可以在Prometheus UI中查看到当前所有的Target状态:
1 http://192.168.224.11:9090/targets?search=
3、常用监控指标 下⾯表格中列举了⼀些CAdvisor中获取到的典型监控指标:
指标名称
类型
含义
container_cpu_load_average_10s
gauge
过去10秒容器CPU的平均负载
container_cpu_usage_seconds_total
counter
容器在每个CPU内核上的累积占⽤时间(单位:秒)
container_cpu_system_seconds_total
counter
System CPU累积占⽤时间(单位:秒)
container_cpu_user_seconds_total
counter
User CPU累积占⽤时间(单位:秒)
container_fs_usage_bytes
gauge
容器中⽂件系统的使⽤量(单位:字节)
container_fs_limit_bytes
gauge
容器可以使⽤的⽂件系统总量(单位:字节)
container_fs_reads_bytes_total
counter
容器累积读取数据的总量(单位:字节)
container_fs_writes_bytes_total
counter
容器累积写⼊数据的总量(单位:字节)
container_memory_max_usage_bytes
gauge
容器的最⼤内存使⽤量(单位:字节)
container_memory_usage_bytes
gauge
容器当前的内存使⽤量(单位:字节
container_spec_memory_limit_bytes
gauge
容器的内存使⽤量限制
machine_memory_bytes
gauge
当前主机的内存总量
container_network_receive_bytes_total
counter
容器⽹络累积接收数据总量(单位:字节)
container_network_transmit_bytes_total
counter
容器⽹络累积传输数据总量(单位:字
4、触发器配置 Prometheus配置
添加docker 触发器(告警规则)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 cat >> prometheus/rules/docker.yml <<"EOF" groups: - name: DockerContainers rules: - alert: ContainerKilled expr: time() - container_last_seen > 60 for: 0m labels: severity: warning annotations: isummary: "Docker容器被杀死 容器: $labels.instance" description: "{{ $value }}个容器消失了" # This rule can be very noisy in dynamic infra with legitimate container start/stop/deployment. - alert: ContainerAbsent expr: absent(container_last_seen) for: 5m labels: severity: warning annotations: summary: "无容器 容器: $labels.instance" description: "5分钟检查容器不存在,值为:{{ $value }}" - alert: ContainerCpuUsage expr: (sum(rate(container_cpu_usage_seconds_total{name!=""}[3m])) BY (instance, name) * 100) > 300 for: 2m labels: severity: warning annotations: summary: "容器cpu使用率告警 容器: $labels.instance" description: "容器cpu使用率超过300%,当前值为:{{ $value }}" - alert: ContainerMemoryUsage expr: (sum(container_memory_working_set_bytes{name!=""}) BY (instance, name) / sum(container_spec_memory_limit_bytes > 0) BY (instance, name) * 100) > 80 for: 2m labels: severity: warning annotations: summary: "容器内存使用率告警 容器: $labels.instance" description: "容器内存使用率超过80%,当前值为:{{ $value }}" - alert: ContainerVolumeIoUsage expr: (sum(container_fs_io_current{name!=""}) BY (instance, name) * 100) > 80 for: 2m labels: severity: warning annotations: summary: "容器存储io使用率告警 容器: $labels.instance" description: "容器存储io使用率超过 80%,当前值为:{{ $value }}" - alert: ContainerHighThrottleRate expr: rate(container_cpu_cfs_throttled_seconds_total[3m]) > 1 for: 2m labels: severity: warning annotations: summary: "容器限制告警 容器: $labels.instance" description: "容器被限制,当前值为:{{ $value }}" EOF
重新加载配置
1 curl -X POST http://localhost:9090/-/reload
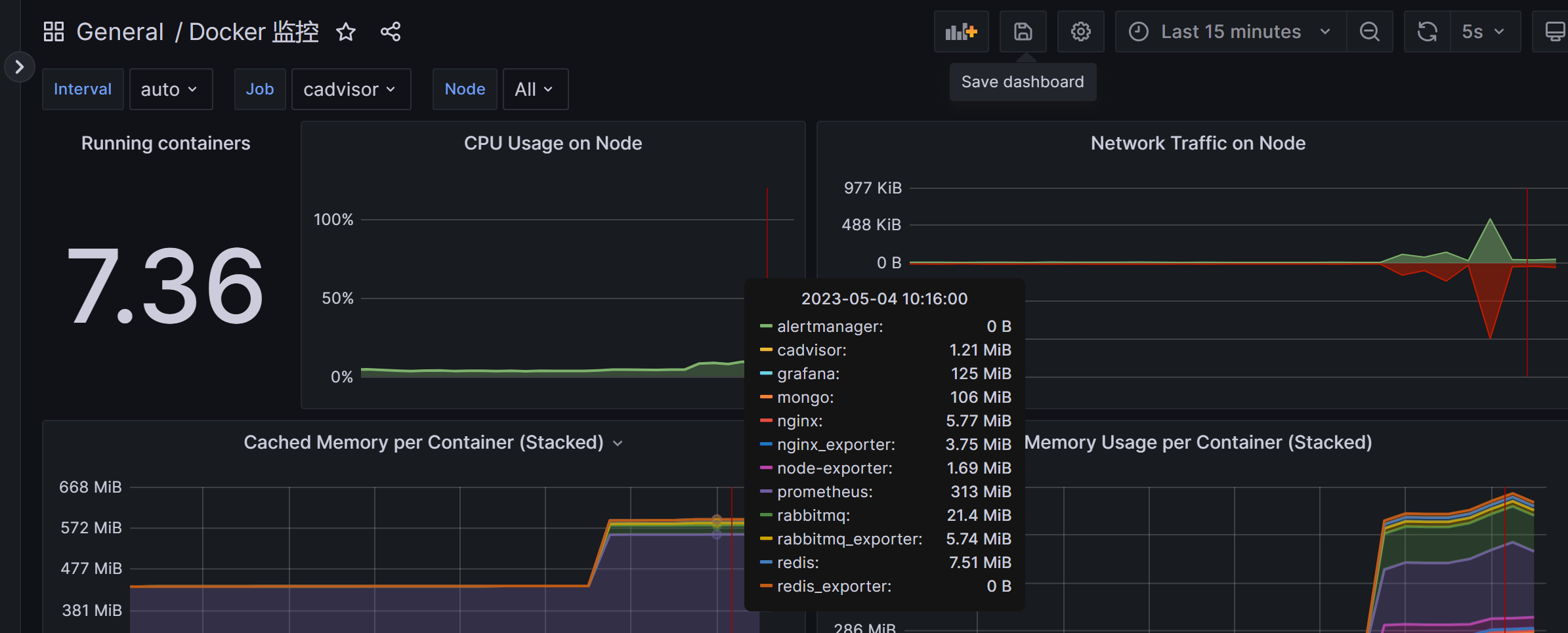
5、dashboard grafana展示prometheus收集到的cadvisor的数据
1 2 3 https://grafana.com/grafana/dashboards/11600-docker-container/ id 11600
七、监控mysql 使⽤docker-compose安装mysql,当然也可以⾃⾏安装
docker-compose 安装mysql
1 2 mkdir /data/mysql -p cd /data/mysql
通过cat创建docker-compose.yaml文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 cat > docker-compose.yaml <<"EOF" version: '3.1' services: db: image: mysql restart: always container_name: mysql environment: TZ: Asia/Shanghai LANG: en_US.UTF-8 MYSQL_ROOT_PASSWORD: 123456 command: --default-authentication-plugin=mysql_native_password --character-set-server=utf8mb4 --collation-server=utf8mb4_general_ci --lower_case_table_names=1 --performance_schema=1 --sql-mode="" --skip-log-bin volumes: #- /data/mysql/conf:/etc/mysql/conf.d #数据文件挂载 - /data/mysql/data:/var/lib/mysql #数据文件挂载 ports: - 3306:3306 EOF
运⾏
检查
STATUS列全部为up 为正常
1、监控mysql mysqld_exporter
1 、创建⽤户
登录mysql
1 2 3 docker exec -it mysql mysql -uroot -p 输⼊密码:12345
创建
1 2 mysql> CREATE USER 'exporter'@'%' IDENTIFIED BY 'password' WITH MAX_USER_CONNECTIONS 3; mysql> GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'%';
验证
1 docker exec -it mysql mysql -uexporter -p
2 、⼆进制安装(⼆选⼀)1 下载地址:https://github.com/prometheus/mysqld_exporter/releases
下载解压后移动**/usr/local/Prometheus**⽬录
1 2 3 4 5 wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.14.0/mysqld_exporter-0.14.0.freebsd-amd64.tar.gz tar zxf mysqld_exporter-0.14.0.freebsd-amd64.tar.gz mv mysqld_exporter-0.14.0.freebsd-amd64 /usr/local/Prometheus/mysqld_exporter
更改exporter ⽂件夹权限
1 chown prometheus.prometheus -R /usr/local/Prometheus/
创建连接数据库的⽂件
1 2 3 4 5 6 7 cat >/usr/local/Prometheus/mysqld_exporter/.mysqld_exporter.cnf << "EOF" [client] user=exporter password=password host=192.168.224.12 port=3306 EOF
创建systemd 服务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 cat > /etc/systemd/system/mysqld_exporter.service << "EOF" [Unit] Description=Prometheus MySQL Exporter After=network.target [Service] Type=simple User=prometheus Group=prometheus Restart=always ExecStart=/usr/local/Prometheus/mysqld_exporter/mysqld_exporter \ --config.my-cnf=/usr/local/Prometheus/mysqld_exporter/.mysqld_exporter.cnf \ --collect.global_status \ --collect.auto_increment.columns \ --collect.info_schema.processlist \ --collect.binlog_size \ --collect.info_schema.tablestats \ --collect.global_variables \ --collect.info_schema.innodb_metrics \ --collect.info_schema.query_response_time \ --collect.info_schema.userstats \ --collect.info_schema.tables \ --collect.perf_schema.tablelocks \ --collect.perf_schema.file_events \ --collect.perf_schema.eventswaits \ --collect.perf_schema.indexiowaits \ --collect.perf_schema.tableiowaits \ --collect.slave_status \ --web.listen-address=0.0.0.0:9104 [Install] WantedBy=multi-user.target EOF
启动 mysqld_exporter
1 2 3 4 5 6 7 systemctl daemon-reload systemctl start mysqld_exporter systemctl enable mysqld_exporter systemctl status mysqld_exporter 启动不了检查⽇志 journalctl -u mysqld_exporter -f
3、docker安装 docker-compose 运⾏
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 mkdir /data/mysqld_exporter -p cd /data/mysqld_exporter cat >docker-compose.yaml<<"EOF" version: '3.3' services: mysqld-exporter: image: prom/mysqld-exporter container_name: mysqld-exporter restart: always command: - '--collect.info_schema.processlist' - '--collect.info_schema.innodb_metrics' - '--collect.info_schema.tablestats' - '--collect.info_schema.tables' - '--collect.info_schema.userstats' - '--collect.engine_innodb_status' environment: - DATA_SOURCE_NAME=exporter:password@(192.168.224.12:3306)/ ports: - 9104:9104 EOF
启动
1 2 3 4 docker-compose up -d 检查 docker ps -a
4、参数解释
Name
MySQL Version
Description
collect.auto_increment.columns
5.1
从 information_schema 收集 auto_increment 列和最⼤值.
collect.binlog_size
5.1
收集所有注册的binlog⽂件的当前⼤⼩
collect.engine_innodb_status
5.1
收集SHOW ENGINE INNODB STATUS
collect.engine_tokudb_status
5.6
收集SHOW ENGINE TOKUDB STATUS .
collect.global_status
5.1
收集SHOW GLOBAL STATUS(默认启⽤)
collect.global_variables
5.1
收集SHOW GLOBAL VARIABLES(默认启⽤)
collect.info_schema.clientstats
5.5
如果以 userstat=1 运⾏,设置为 true 以收集客户端统计信息
collect.info_schema.innodb_metrics
5.6
从 information_schema.innodb_metrics收集指标
collect.info_schema.innodb_tablespaces
5.7
从information_schema.innodb_sys_tablespaces收集指标
collect.info_schema.innodb_cmp
5.5
从information_schema.innodb_cmp收集 InnoDB 压缩表指标。
collect.info_schema.innodb_cmpmem
5.5
从information_schema.innodb_cmpmem缓冲池压缩指标。
collect.info_schema.processlist
5.1
从 information_schema.processlist 收集线程状态计数
collect.info_schema.processlist.min_time
5.1
线程必须处于要计算的每个状态的最短时间。 (默认值:0)
collect.info_schema.query_response_time
5.5
如果 query_response_time_stats 为 ON,则收集查询响应时间分布。
collect.info_schema.replica_host
5.6
从 information_schema.replica_host_status 收集指标。
collect.info_schema.tables
5.1
从information_schema.tables收集指标。
collect.info_schema.tables.databases
5.1
要为其收集表统计信息的数据库列表,或为所有
collect.info_schema.tablestats
5.1
如果以 userstat=1 运⾏,设置为 true 以收集表统计信息。
collect.info_schema.schemastats
5.1
如果以 userstat=1 运⾏,设置为 true 以收集架构统计信息
collect.info_schema.userstats
5.1
如果以 userstat=1 运⾏,设置为 true 以收集⽤户统计信息。
collect.mysql.user
5.5
从 mysql.user 表中收集数据
collect.perf_schema.eventsstatements
5.6
从 performance_schema.events_statements_summary_by_digest 收集指标。
collect.perf_schema.eventsstatements.digest_text_limit
5.6
规范化语句⽂本的最⼤⻓度。 (默认值:120)
collect.perf_schema.eventsstatements.limit
5.6
按响应时间限制事件语句摘要的数量。 (默认值:250)
collect.perf_schema.eventsstatements.timelimit
5.6
以秒为单位限制“last_seen”事件语句的存在时间。 (默认值:86400)
collect.perf_schema.eventsstatementssum
5.7
从 performance_schema.events_statements_summary_by_digest 汇总收集指标。
collect.perf_schema.eventswaits
5.5
从performance_schema.events_waits_summary_global_by_event_name收集指标
collect.perf_schema.file_events
5.6
从 performance_schema.file_summary_by_event_name 收集指标
collect.perf_schema.file_instances
5.5
从 performance_schema.file_summary_by_instance 收集指标。
collect.perf_schema.file_instances.remove_prefix
5.5
删除 performance_schema.file_summary_by_instance 中的路径前缀。
collect.perf_schema.indexiowaits
5.6
从 performance_schema.table_io_waits_summary_by_index_usage收集指标。
collect.perf_schema.memory_events
5.7
从 performance_schema.memory_summary_global_by_event_name收集指标。
collect.perf_schema.memory_events.remove_prefix
5.7
删除performance_schema.memory_summary_global_by_event_name 中的仪器前缀
collect.perf_schema.tableiowaits
5.6
从 performance_schema.table_io_waits_summary_by_table 收集指标
collect.perf_schema.tablelocks
5.6
从 performance_schema.table_lock_waits_summary_by_table 收集指标
collect.perf_schema.replication_group_members
5.7
从 performance_schema.replication_group_members 收集指标
collect.perf_schema.replication_group_member_stats
5.7
从 performance_schema.replication_group_member_stats 收集指标
collect.perf_schema.replication_applier_status_by_worker
5.7
从 performance_schema.replication_applier_status_by_worker 收集指标
collect.slave_status
5.1
从 SHOW SLAVE STATUS 收集(默认启⽤)
collect.slave_hosts
5.1
从 SHOW SLAVE HOSTS 收集
collect.heartbeat
5.1
从⼼跳收集
collect.heartbeat.database
5.1
从哪⾥收集⼼跳数据的数据库。 (默认:⼼跳)
collect.heartbeat.table
5.1
从哪⾥收集⼼跳数据的表。 (默认:⼼跳)
collect.heartbeat.utc
5.1
使⽤ UTC 作为当前服务器的时间戳(使⽤ –utc 调⽤ pt-heartbeat )。 (默认值:假)
5、Prometheus配置 配置prometheus去采集(拉取)mysql_exporter的监控样本数据
1 2 3 4 5 6 7 8 9 10 cd /data/docker-prometheus #在scrape_configs(搜刮配置):下⾯增加如下配置: cat >> prometheus/prometheus.yml << "EOF" - job_name: 'mysqld_exporter' static_configs: - targets: ['192.168.224.12:9104'] labels: instance: server2.com服务器 EOF
重新加载配置
1 curl -X POST http://localhost:9090/-/reload
6、常用监控指标 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 mysql_up # 服务器是否在线 mysql_global_status_uptime # 运行时长,单位 s delta(mysql_global_status_bytes_received[1m]) # 网络接收的 bytes delta(mysql_global_status_bytes_sent[1m]) # 网络发送的 bytes mysql_global_status_threads_connected # 当前的客户端连接数 mysql_global_variables_max_connections # 允许的最大连接数 mysql_global_status_threads_running # 正在执行命令的客户端连接数,即非 sleep 状态 delta(mysql_global_status_aborted_connects[1m]) # 客户端建立连接失败的连接数,比如登录失败 delta(mysql_global_status_aborted_clients[1m]) # 客户端连接之后,未正常关闭的连接数 delta(mysql_global_status_commands_total{command="xx"}[1m]) > 0 # 每分钟各种命令的次数 delta(mysql_global_status_handlers_total{handler="xx"}[1m]) > 0 # 每分钟各种操作的次数 delta(mysql_global_status_handlers_total{handler="commit"}[1m]) > 0 # 每分钟 commit 的次数 delta(mysql_global_status_table_locks_immediate[1m]) # 请求获取锁,且立即获得的请求数 delta(mysql_global_status_table_locks_waited[1m]) # 请求获取锁,但需要等待的请求数。该值越少越好 delta(mysql_global_status_queries[1m]) # 每分钟的查询数 delta(mysql_global_status_slow_queries[1m]) # 慢查询数。如果未启用慢查询日志,则为 0 mysql_global_status_innodb_page_size # innodb 数据页的大小,单位 bytes mysql_global_variables_innodb_buffer_pool_size # innodb_buffer_pool 的限制体积 mysql_global_status_buffer_pool_pages{state="data"} # 包含数据的数据页数,包括洁页、脏页 mysql_global_status_buffer_pool_dirty_pages # 脏页数
7、触发器配置 添加mysql 触发器(告警规则)
1 cd /data/docker-prometheus
使⽤cat创建⽂件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 cat >> prometheus/rules/mysqld.yml <<"EOF" groups: - name: MySQL rules: - alert: MysqlDown expr: mysql_up == 0 for: 30s labels: severity: critical annotations: summary: "MySQL Down,实例:{{ $labels.instance }}" description: "MySQL_exporter连不上MySQL了,当前状态为:{{ $value }}" - alert: MysqlTooManyConnections expr: max_over_time(mysql_global_status_threads_connected[1m]) / mysql_global_variables_max_connections * 100 > 80 for: 2m labels: severity: warning annotations: summary: "Mysql连接数过多告警,实例:{{ $labels.instance }}" description: "MySQL连接数>80%,当前值:{{ $value }}" - alert: MysqlHighThreadsRunning expr: max_over_time(mysql_global_status_threads_running[1m]) > 20 for: 2m labels: severity: warning annotations: summary: "Mysql运行的线程过多,实例:{{ $labels.instance }}" description: "Mysql运行的线程 > 20,当前运行的线程:{{ $value }}" - alert: MysqlSlowQueries expr: increase(mysql_global_status_slow_queries[2m]) > 0 for: 2m labels: severity: warning annotations: summary: "Mysql慢日志告警,实例:{{ $labels.instance }}" description: "MySQL在过去2分钟有新的{{ $value }}条慢查询" #MySQL innodb 日志写入停滞 - alert: MysqlInnodbLogWaits expr: rate(mysql_global_status_innodb_log_waits[15m]) > 10 for: 0m labels: severity: warning annotations: summary: "MySQL innodb日志等待,实例:{{ $labels.instance }}" description: "MySQL innodb日志写入停滞,当前值: {{ $value }}" - alert: MysqlRestarted expr: mysql_global_status_uptime < 60 for: 0m labels: severity: info annotations: summary: "MySQL 重启,实例:{{ $labels.instance }}" description: "不到一分钟前,MySQL重启过" EOF
配置检查
1 docker exec -it prometheus promtool check config /etc/prometheus/prometheus.yml
重新加载配置
1 curl -X POST http://localhost:9090/-/reload
检查
1 http://192.168.224.11:9090/alerts?search=
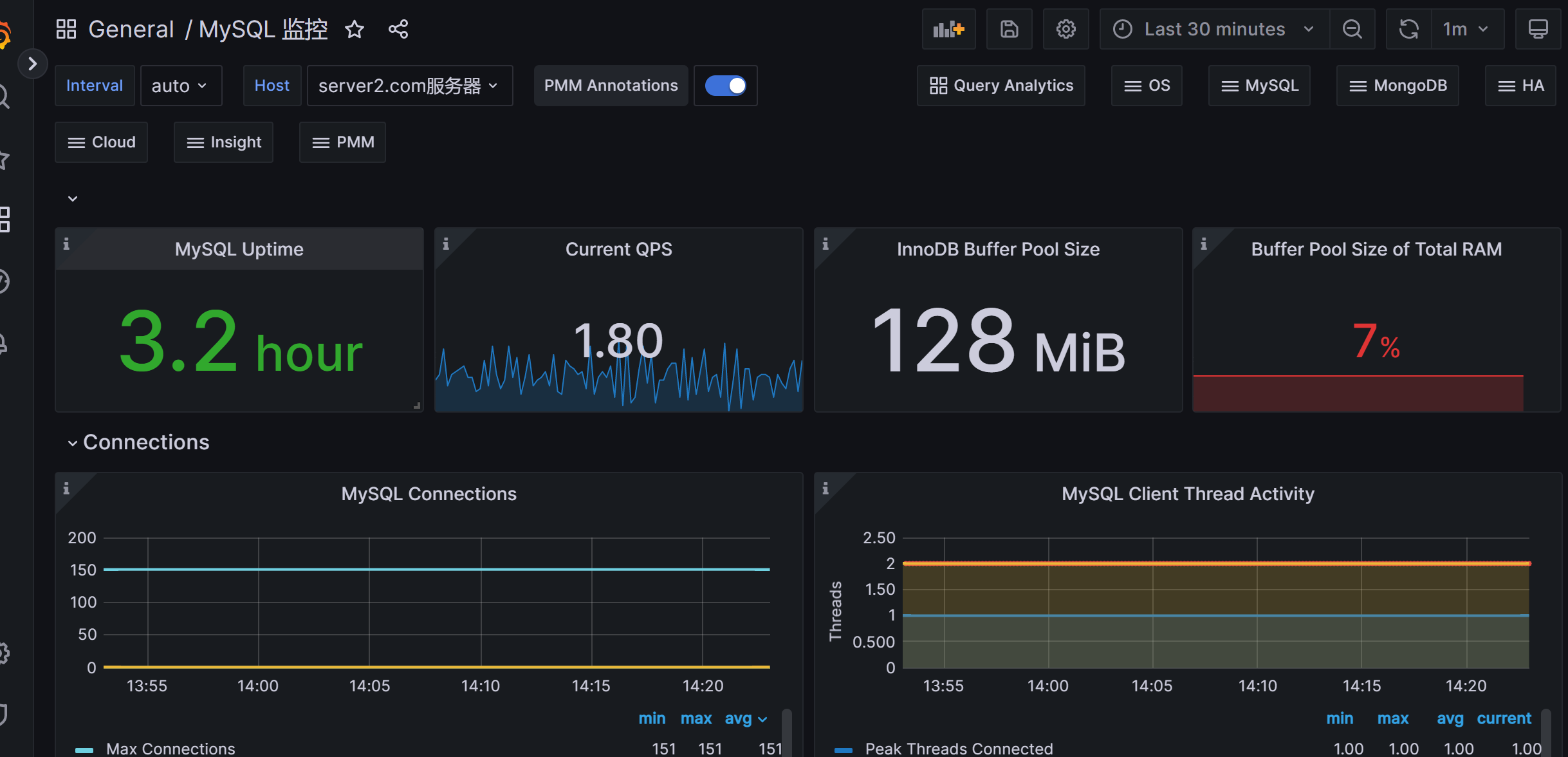
8、dashboard grafana展示prometheus从mysql_exporter收集到的的数据
1 2 3 https://grafana.com/grafana/dashboards/7362 https://github.com/percona/grafana-dashboards/tree/main/dashboards/MySQL
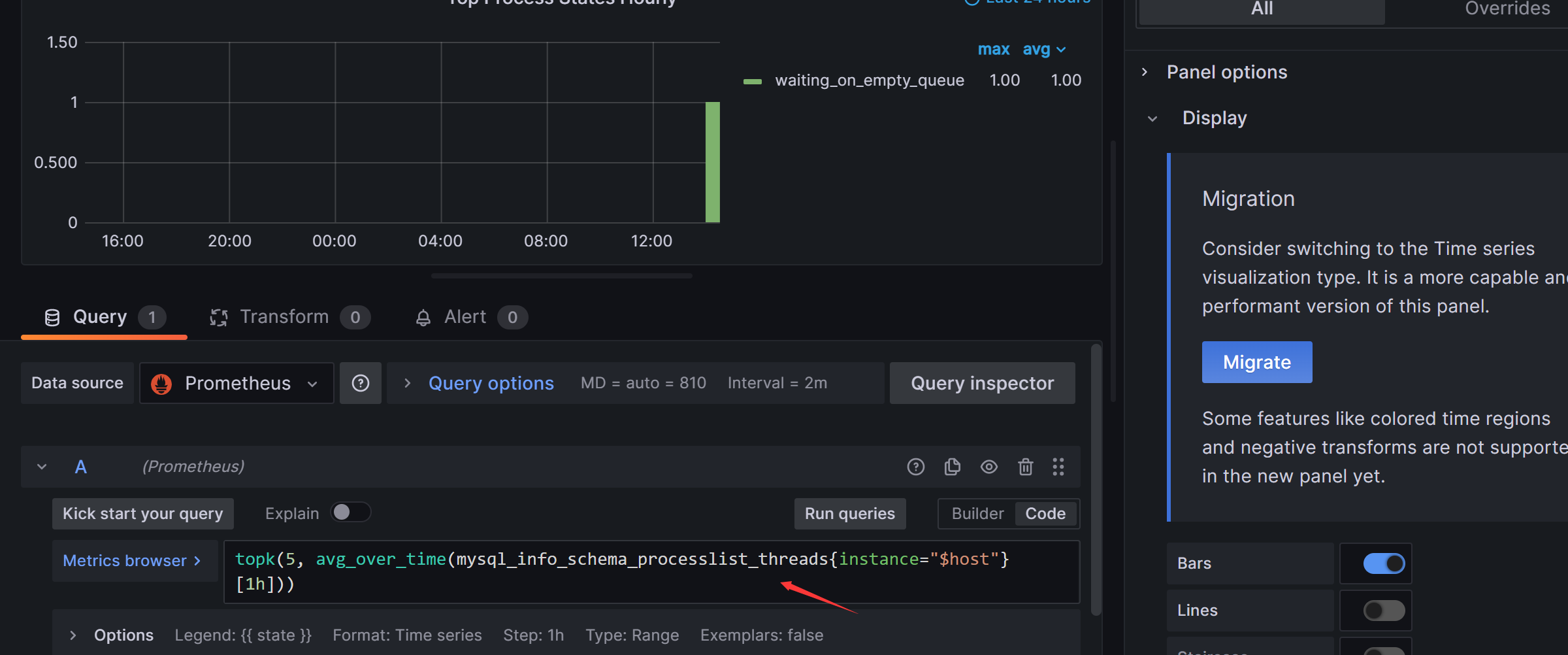
Top Process States和 Process States图形修改为如下:
mysql_info_schema_threads 替换成:
mysql_info_schema_processlist_threads
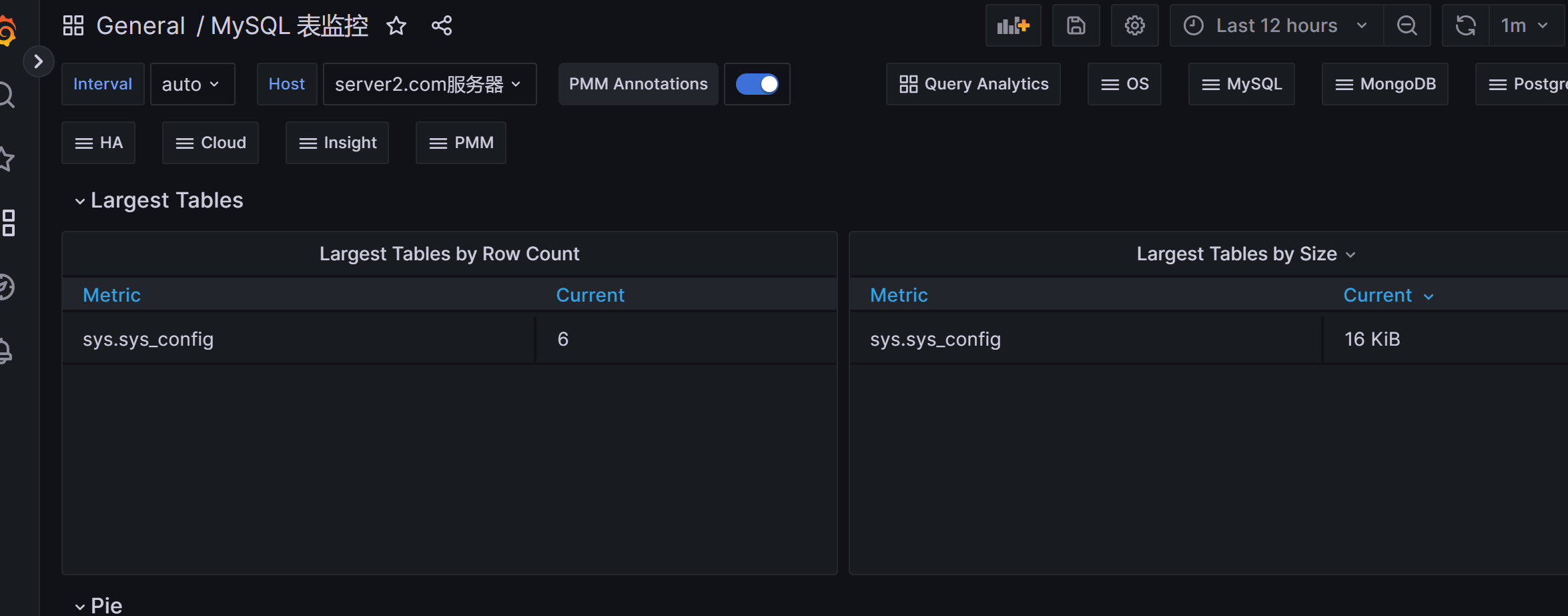
数据库表监控
1 https://grafana.com/grafana/dashboards/9625
注意:2个图表没有数据,是因为只⽀持percona server 和 mariadb